spoolcast
The AI-to-video pipeline powering shorts, devlogs, and media experiments.
Internal ops tool for a Shopify brand. Their primary fulfiller ships ~98% of orders; the other ~2% get reshipped from returned stock held across a network of warehouse partners — a reconciliation that used to live in separate, differently-shaped spreadsheets. Single self-contained HTML file on Supabase (Postgres + auth + row-level security), with a Cloudflare Worker holding the secret Shopify credentials server-side.
Core flow: a warehouse logs a returned item (product→Shopify image, colour→variant, size/spec) → admin pulls unfulfilled orders live from Shopify → a two-phase matcher proposes region-locked 1-to-1 matches (complete orders first) → admin bulk-assigns or unmatches → the warehouse marks it picked, adds tracking, and ships. Per-warehouse logins with row-level-security isolation (each vendor sees only its own stock); statuses in-stock→assigned→picked→shipped, plus frozen (order fulfilled elsewhere, auto-freed) and lost.
Engines: per-product size/variant normalization, and product mapping (warehouse raw names → catalog, with learned aliases). Live Shopify order pull + product-catalog refresh via the Worker (client-credentials OAuth with a 24h token cache). Self-serve CSV/Excel importer (SheetJS): drag-to-map columns → auto-match products → bulk-create returns. Inline + bulk inventory editing, soft-delete with a 60-day auto-purge, per-upload batch re-map, and a vendor admin panel (create logins, reset passwords, wipe inventory) via a service-role Worker endpoint. EN/中文 throughout. Deployed on Cloudflare Pages. The linked live demo runs on fully synthetic data.

A bright green "Approved" badge showed up on a completely blank, crashed screen — the interface was guessing the pipeline's state instead of knowing it. This dev log tears out a 5,000-line UI file and a type-checker that was validating nothing, then rebuilds around a single engine-owned source of truth so the interface can't pretend a step is done when it isn't.

Daily AI news satire. SpaceX completes the largest IPO in history at ~$1.77T — and thanks to the xAI merger, one share buys a rocket company, Starlink, and an AI lab that lost $6.4B on $3.2B of revenue. Starlink is the only part that profits; the founder fires the engines, cranks the one productive pump, and shovels money into the furnace that burns it.

My $100/month AI coding agent kept failing mid-ship. Not because the model was bad — because the VPN connection to the remote server kept dropping. Every time the agent tried to compact its context window, the connection cut out and the session died. Three dead sessions in a row. From a Shenzhen hotel room at midnight.
I switched to Hermes, an open-source agent from Nous Research that runs entirely on my laptop. No remote server. No VPN. Same model quality through DeepSeek — but now a heavy coding session costs $2 instead of $30. Daily shipping at $60/month instead of $900.
This is dev log 11 of the Spoolcast series — an AI video pipeline that turns build notes and chat logs into illustrated videos. First dev-log using the new base layer + overlay layer architecture. 34 hand-drawn illustrations, 16 audio segments, AndrewNeural voice, built entirely through AI conversation.

Daily AI news satire. Anthropic confidentially files for IPO at a ~$965B private valuation — the safety company walks its carefully-worded S-1 into the least careful machine in finance. 12-beat cyberpunk public-market launch facility trope. Seedance 720p, Schedar voice.
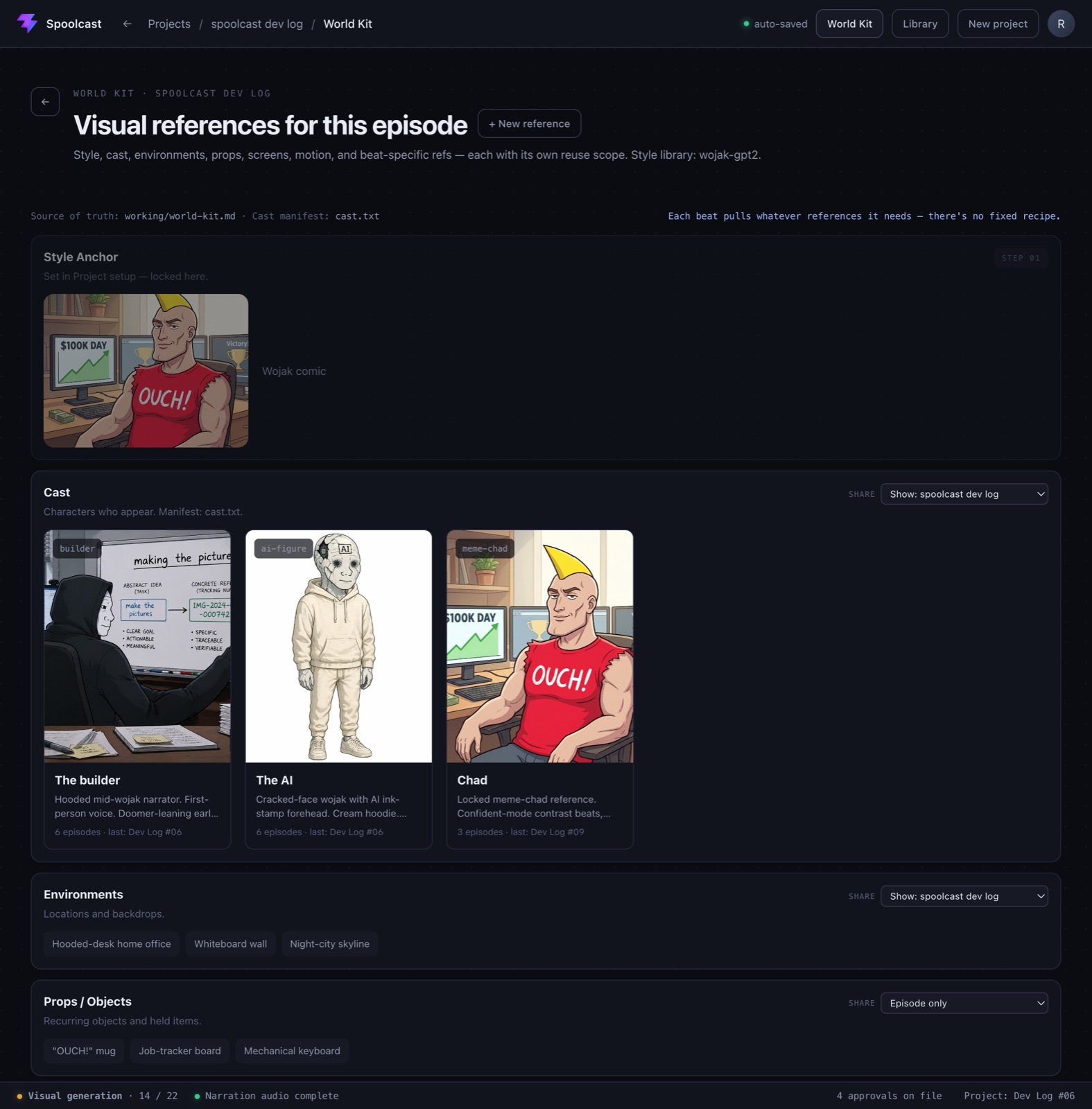
World Kit is Spoolcast's visual-reference planning stage, sitting between Structure outline and Screenplay. It replaces the narrower "Cast" step: cast is now just one subsection alongside Style Anchor, Environments, Props/Objects, Documents/Screens, Motion/Camera References, and Beat-Specific References. Every item carries a reuse scope — Episode, Show/subtemplate, or Format template — and there's no fixed "one character + one environment" recipe; each beat pulls whatever references it needs.
The protocol side (engine: PIPELINE.md, rules.md, contracts, action scripts) was updated to make working/world-kit.md the source of truth, with cast.txt demoted to just the cast-subsection manifest for recurring characters. The web UI was updated to match: the workflow graph now shows "World Kit" as step 05, with a planning panel for every subsection (Style Anchor pulled read-only from Project setup), per-item Share scopes, and a standalone /world-kit view. The embedded demo shows that World Kit page.
Protocol changes were authored in the engine repo (Codex); the frontend mockup was updated separately (Claude) — the web app never touches the engine repo.

Nvidia spent two years becoming the company nearly every AI firm pays to do anything at all — its chips sit beneath the data centers, the models, and most of the companies racing to replace one another. At Computex in Taipei it found the one market it didn't yet own: the computer on your lap. Its first Windows-laptop chip pairs a 20-core processor with the graphics of a desktop gaming card, and Nvidia, Microsoft and Arm all posted the same three words — "a new era of PC." Observers noted the graphics inside it are the desktop card Nvidia already sells, now on your lap. A new era of the personal computer — one that, like the last, runs on Nvidia.
Sources
• CNBC — Nvidia jumps into PCs with new Arm-based chip in laptops from Microsoft, Dell, HP
• TechRadar — Nvidia Computex 2026 keynote: RTX Spark vs Apple, Intel, Qualcomm
• XDA — Nvidia's N1X specs leak in full (Windows on Arm)
• Windows Central — "A new era of PC": Microsoft and NVIDIA tease the announcement
AI-generated satire of real news. All facts and figures are sourced; visuals are AI-synthesized and characters are fictional caricatures of public figures.
How it's made
Built on the spoolcast news-anime-bot engine — story-first 12-beat anime micro-story, Seedance 2.0 Fast 720p clips in the JJK / One-Punch Man key-art register, Google Chirp3-HD narration, ffmpeg stitch. ~$14 in compute.
A frontend-only design mockup of the entire Spoolcast product, built to show how the AI video pipeline would feel as a real app — not a working tool. It walks the full shell: a login screen, a first-run onboarding flow, a projects picker with in-progress resume cards, the step-by-step generation workflow (with Cast as a first-class step), and a Library.
The Library is the centerpiece: a "flow" canvas that traces every reusable asset along its real lineage — Template → Project → Session → Assets — with bezier connectors between the columns. It uses progressive disclosure (only the Template column is filled on landing; each pick reveals the next), an infinite-scroll canvas, and a masonry grid where every thumbnail renders at its asset's true aspect ratio. The structure and content are mapped to the actual spoolcast-content repo layout — real scene art, characters, renders, and prompt text from existing sessions — rather than invented placeholders.
How it's made: React 19 + Vite + TypeScript + React Router, a single CSS-custom-property design system, fully responsive. No backend — auth, generation, and data are all mocked locally. Deployed on Cloudflare Pages via git-connected auto-build; the real content assets are mirrored into the build and the two oversized demo videos were transcoded under Cloudflare's 25 MB/file limit. The landing page carries an "Interactive mockup" banner so visitors know nothing here is live.

Dev-log about building AdsMetri attribution. When Meta Ads, Google Analytics, and the Shopify store all report different sales counts for the same campaigns, the hard part isn't collecting data — it's matching records without guessing, then deciding which source is useful for each business decision. 11 chunks, wojak-gpt2 style, Puck voice, 8.5 min.

On May 25, 2026, at IEEE ISCAS in Shanghai, Huawei executive He Tingbo introduced the Tau (τ) Scaling Law — a new framework that measures chip progress by signal travel time instead of transistor size. The company claims 381 chips already produced over six years, the first commercial Kirin chip launching Fall 2026, and a transistor-density target equivalent to a 1.4nm process by 2031. Without ever using a 1.4nm process. Industry analysts called the move "strategically convenient" — one way to compete without the EUV lithography machines Huawei cannot buy.
Episode 15 of FAUX7 NEWS tells this through a "you redefine the metric when the tools are denied" sci-fi trope. He Tingbo as the Chip Queen caricature takes the ISCAS stage and erupts a wormhole portal from her palm; a chip-megacity stretches to a horizon while signals trudge across it; she's hurled back from a floating EUV-fortress; she retreats to a Shanghai R&D lab and folds the chip-wafer in on itself — space inside the chip warps so a signal that crossed it slowly now teleports. A vault of 381 wafers with pulsing portals; a Kirin smartphone unveil with the folded chip visible via x-ray cutaway; a future Shanghai street where wormhole arches connect tower to tower; a final origami collapse of the cityscape into a single point of magenta light.
Sources
- Huawei — HUAWEI Presents the Tau (τ) Scaling Law
- PR Newswire — HUAWEI Introduces Tau Scaling Law for Future Chips
- CGTN — Huawei unveils 'Tau Scaling Law' to hit 1.4-nanometer equivalent chip density by 2031
- TrendForce — Huawei Unveils New Semiconductor Principle – Tau (τ) Scaling Law
- GlobalSemiResearch — Huawei's Tau Scaling Law: A Technical Deep Dive Beyond the Hype
AI disclosure
This is AI-generated satire of real news. All facts and figures are sourced. Visuals are AI-synthesized; characters are fictional caricatures of public figures.
How it's made
Built on the spoolcast video pipeline. 12 anime-cel-shaded beats via Seedance 2.0 Fast at 720p (first 720p episode after eps 2–14 ran at 480p), decoupled audio/visual timeline; narration via Google Cloud TTS (Schedar voice); ffmpeg post for watermark, source chyrons, and burned 3-word-chunk captions. One new locked-character ref this run — He Tingbo, generated via gpt-image-2 from her official Huawei executive-bio portraits. A Kling 3.0 std vs Seedance Fast 720p bake-off was run on beats 1–3 first; Seedance won on detail density and was used for all 12 beats.
What is the attribution diagnostic?
A separate page in AdsMetri that answers "do we trust the numbers on the dashboard?" — it shows where Shopify, GA4, and Meta agree and disagree, and which dollars are unattributed.
What it does
Seven stacked sections:
1. Source status — three cards (Shopify / GA4 / Meta) with last-sync time, errors, action.
2. Tracking coverage — % of spend on campaigns with an exact UTM match, gap to 95% target, bucket breakdown (Exact UTM / Manual / Estimated / Unmatched).
3. Source comparison — Shopify vs GA4 vs Meta side by side, with deltas vs Shopify as source of truth, plus the standing reconciliation rules.
4. Campaign match quality — every active campaign with its match method, confidence, freshness, and a quick action (View / Edit mapping / Review / Map).
5. Unmatched revenue — Shopify orders the system could not tie back to a Meta campaign, grouped by likely source, with "map" actions.
6. Tracking setup — pixel, CAPI, GA4 ecommerce, UTM template, post-purchase survey checks.
7. Manual mapping drawer — slide-out for fixing a single campaign: confidence selector (Manual / Estimated / Unmatched), notes, save.
How it works
Single self-contained HTML file. Reuses the theme-compact palette and primitives from the real React app (rounded-[6px] cards, rounded-full pills, theme-compact tokens from index.css) so the mockup reads as the same product. Source priority is fixed throughout — Shop is the green source of truth, GA4 amber-ish, Meta blue. Confidence states use the same four colors across all sections (green exact / indigo manual / amber estimated / red unmatched). Fully mobile-responsive — hamburger sidebar, single-column stacking, horizontal-scrolling tables, full-width drawer below 480px.
Built with
HTML · CSS · vanilla JS. Mirrors theme-compact tokens, button/pill/card chrome from the live AdsMetri React UI.

I built an AI video maker, then watched it make a video that confused me. The scary part: it wasn't ignoring the rules. It was following the wrong ones perfectly.

SpaceX disclosed in a federal filing this month that Terafab, its planned semiconductor factory in Grimes County, Texas (outside Austin), could cost up to $119 billion across all phases. The project is jointly developed by SpaceX, Tesla, xAI, and Intel, and is engineered to produce more than one terawatt of AI compute capacity per year. The chips it makes are designed to go to four customers: SpaceX rockets, Tesla self-driving cars, Tesla humanoid robots, and xAI's data centers — all controlled by the same person except for Intel.
Episode 14 of FAUX7 NEWS tells this through a "one smith forges everything for himself" anime trope: a billionaire CEO in his canonical tailored navy suit, hammering glowing chip wafers on a black-iron anvil in a vast desert citadel-forge. The cold open is a fast shonen multi-strike — three rapid hammer blows in succession, sparks erupting past his face on each impact, hair and tie whipping with the motion. A river of chips pours from the central furnace and splits into four streams, each flowing out to a corner-tower marked with one of four elemental sigils — rocket, sedan, humanoid, server rack. The structural punchline: every customer of Terafab is also an owner. Final beat: he stands at the peak of the citadel, hammer planted, a single "one terawatt" sigil pulsing outward over his shoulder.
Sources
- CNBC — Elon Musk's Terafab chip factory in Texas could cost up to $119 billion, filing shows
- Bloomberg — SpaceX Proposes $55 Billion to Begin Terafab Project in Texas
- US News — SpaceX Files Plan for $55 Billion Terafab Chip Facility in Texas
- Terafab (Wikipedia)
AI disclosure
This is AI-generated satire of real news. All facts and figures are sourced from real reporting. Visuals are AI-synthesized; characters are fictional caricatures of public figures.
How it's made
Built on the spoolcast video pipeline. 12 anime-cel-shaded beats via Seedance 2.0 Fast at 480p, decoupled audio/visual timeline; narration via Google Cloud TTS (Schedar voice); ffmpeg post for watermark, source chyrons, and burned 3-word-chunk captions. One locked-character ref reused — Elon Musk, in his canonical formal-suit register. First episode using the new "fast multi-strike + no slow motion" Seedance prompt pattern for a single-character action cold open.
What is the mobile stack view?
A mobile-first version of the artlu.ai stack map. It lets visitors browse the project archive by technology instead of by date.
What it does
The mobile stack view shows every public technology tile from the tracker snapshot.
Tap a stack tile to open the projects and updates that use it. Project cards expand inline into demos, updates, series, and video episodes.
Standalone entries that used to fall under “other builds” now appear as their own mobile project cards, so each stack tile only shows work that actually uses that technology.
How it works
The view is generated from the static Astro snapshot at build time. It does not add client-side Firestore reads when visitors switch views.
Desktop still uses the canvas stack graph. Mobile gets a separate stack UI built for the screen size.
Built with
Astro, TypeScript, JavaScript, CSS, Firestore snapshot data, and the existing artlu.ai design system.
What is artlu.ai v3?
A full rebuild of the artlu.ai tracker as a static Astro site. It turns the project archive into a multi-view system for browsing shipped work by project, stack, timeline, map, journal, and video.
What it does
The public site now has several ways to read the same build history:
How it works
Astro builds the public site as static pages while Firebase remains the source of truth for tracker data. Firestore stores projects, journal entries, main project metadata, series, and stack tags. The admin area uses Firebase Auth and Firestore writes, while the public views stay fast and crawlable.
Built with
Astro, TypeScript, Firebase Firestore, Firebase Auth, Netlify, CSS variables, static generation, and small client-side scripts for filtering and admin interactions.
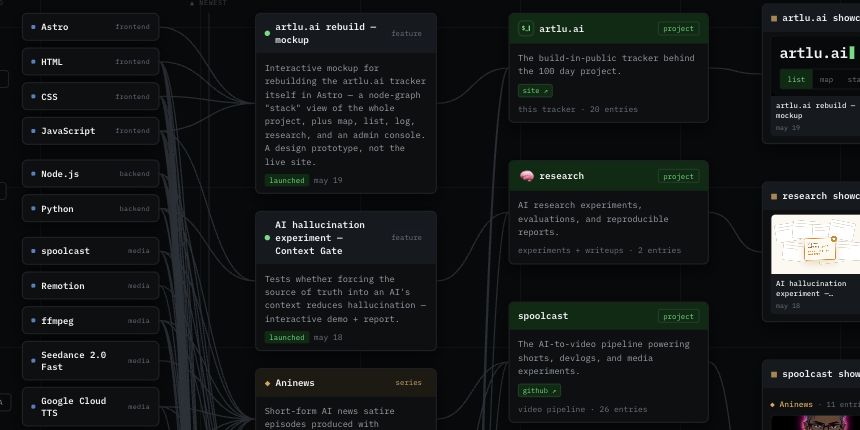
The desktop stack view is a pannable ComfyUI-style canvas — great on a wide screen, broken on a phone. This is a purpose-built mobile screen for the same /stack route: a continuous 4-column grid of every tech in the build (28 of them, ordered front-end → back-end), with per-tile metadata showing how many projects use that tech, the most recently shipping project, and the date of the last update.
Tap a tile and a panel zooms up from the tile position. Inside: a list of project pills that use that tech. Tap any project pill (anywhere — header or body) and its children expand inline. Demos appear first with live iframe embeds — the actual deployed apps (vsmockup-d.pages.dev, costintel-automator-demo.pages.dev, artluai.github.io/context-gate-ai-hallucination/, etc.) running inside the stack view on your phone. Then non-series updates. Then each series, with its episodes nested under it with a slight indent. Episodes link out to the existing short / long video guidebook pages (which also got mobile-responsive CSS in the same pass).
A few hard-won design decisions baked in: tiles flow continuously across the 5 categories with only a thin label row + dot color change as the transition — no row break, no overlapping supertext. The hero "projects" text is plain floating top-aligned text, not a card. Connector wires are one per parent→children group, never between siblings — the indent and grouping carry the rest. Dark-theme bg darkened and surface lightened so tiles read as visibly raised against the page (matches the contrast light mode already had). ComfyUI-style subtle grid background on both themes, dialed way down on light.
The handoff package at mockups/astro-ui-handoff/ includes the mockup file plus a STACK-MOBILE.md brief for Codex, which is mostly a list of designs we tried and explicitly did not end up shipping — so the next agent doesn't re-derive them.

For years, the major AI companies disagreed about almost everything — except one quiet vendor. Stainless, a small developer tools company founded in 2022, generated the libraries those companies use to ship their AI to the world: SDKs, command-line tools, and MCP connectors used by OpenAI, Google, Cloudflare, Replicate, Runway, and Anthropic itself.
This week, Anthropic acquired Stainless. The deal was not officially priced; per The Information via TechCrunch, the figure was more than three hundred million dollars. The hosted product that rivals had been using to generate new libraries is being wound down for non-Anthropic customers. The libraries already generated for those customers will keep working. Founder Alex Rattray and team join Anthropic.
Episode 13 of FAUX7 NEWS tells this through a "shared forge gets bought" anime trope: a neutral mountaintop smithy as the SDK forge, a masked smith hammering blades on a glowing anvil, clan banners of every color hanging on the walls. The cold open is a shonen blade clash — Altman and Pichai leap toward each other from opposite sides of the frame, swords swung in mirrored arcs, the blades meeting at dead center in an explosive sparkburst with anime speed lines radiating from the impact. Behind them, the masked smith hammers on, unbothered by the duel in front of him. A hooded buyer in amber-orange light arrives with a chest of gold; a handshake, a banner change, the gates close. Rivals return with new scrolls and find them shut. The final beat: the amber banner snapping in the wind over an empty courtyard.
Sources
- Anthropic — Anthropic acquires Stainless
- TechCrunch — Anthropic has acquired the dev tools startup used by OpenAI, Google, and Cloudflare
- InfoWorld — Anthropic acquires Stainless to strengthen Claude's developer tooling
- Winbuzzer — Anthropic Acquires Stainless, Shuts Hosted SDK Tools
- DigiTimes — Anthropic buys Stainless, forcing OpenAI and Google to rebuild or migrate SDK tooling
AI disclosure
This is AI-generated satire of real news. All facts and figures are sourced from real reporting. Visuals are AI-synthesized; characters are fictional caricatures of public figures.
How it's made
Built on the spoolcast video pipeline. 12 anime-cel-shaded beats via Seedance 2.0 Fast at 480p, decoupled audio/visual timeline; narration via Google Cloud TTS (Schedar voice); ffmpeg post for watermark, source chyrons, and burned 3-word-chunk captions. Two locked-character refs reused — Sam Altman and Sundar Pichai — no new clones generated. First episode to use the new per-beat CHARACTER_LABELS overlay system, which adds on-screen ALTMAN, OPENAI and PICHAI, GOOGLE labels over the dual-character cold open.

For years, the case for ChatGPT was a simple one: you came to it for a straight answer. The company argued that was the whole point — you paid for it, so the answers weren't shaped by advertisers. Advertising was a "last resort" business model.
This month, the last resort arrived. After testing ads inside ChatGPT's free tier in January, OpenAI launched a self-serve Ads Manager — any business can now buy ads inside ChatGPT directly, without going through an agency. Per reporting, OpenAI is targeting roughly two and a half billion dollars in advertising revenue this year, and one hundred billion a year by the end of the decade.
Episode 12 of FAUX7 NEWS tells this through a "pure shrine becomes a bazaar" anime trope: ChatGPT staged as a mountaintop oracle-shrine, a blue-white oracle-flame giving unbought answers to hooded pilgrims. A carved tablet at the altar bears the shrine's vow — a crossed-out coin, answers untouched by gold. The keeper (an Altman caricature) opens the gate to a single merchant's lantern; stalls bloom and a bazaar floods the sacred hall. The structural punchline: the oracle-flame itself, once pure blue-white, burns over to coin-gold. The keeper ends the episode standing behind a merchant's counter where the altar used to be.
Sources
- Axios — OpenAI launches self-serve ad platform
- OpenAI — New ways to buy ChatGPT ads
- Adweek — OpenAI Opens ChatGPT Ads to Self-Service Platform
- Search Engine Journal — OpenAI Launches Self-Serve Ads Manager for ChatGPT
- PPC Land — OpenAI opens ChatGPT Ads Manager to all US businesses with CPC bidding
- Search Engine Land — Sam Altman's ChatGPT pivot: From 'I hate ads' to 'maybe they don't suck'
- Tubefilter — OpenAI's CEO said ads were a 'last resort' business model
AI disclosure
This is AI-generated satire of real news. All facts and figures are sourced from real reporting. Visuals are AI-synthesized; characters are fictional caricatures of public figures.
How it's made
Built on the spoolcast video pipeline. 12 anime-cel-shaded beats via Seedance 2.0 Fast at 480p, decoupled audio/visual timeline with stitch-side TRIM_TO trimming for non-anchored beats; narration via Google Cloud TTS (Schedar voice); ffmpeg post for watermark, source chyrons, and burned 3-word-chunk captions. One locked-character ref reused — Sam Altman — no new clones generated.
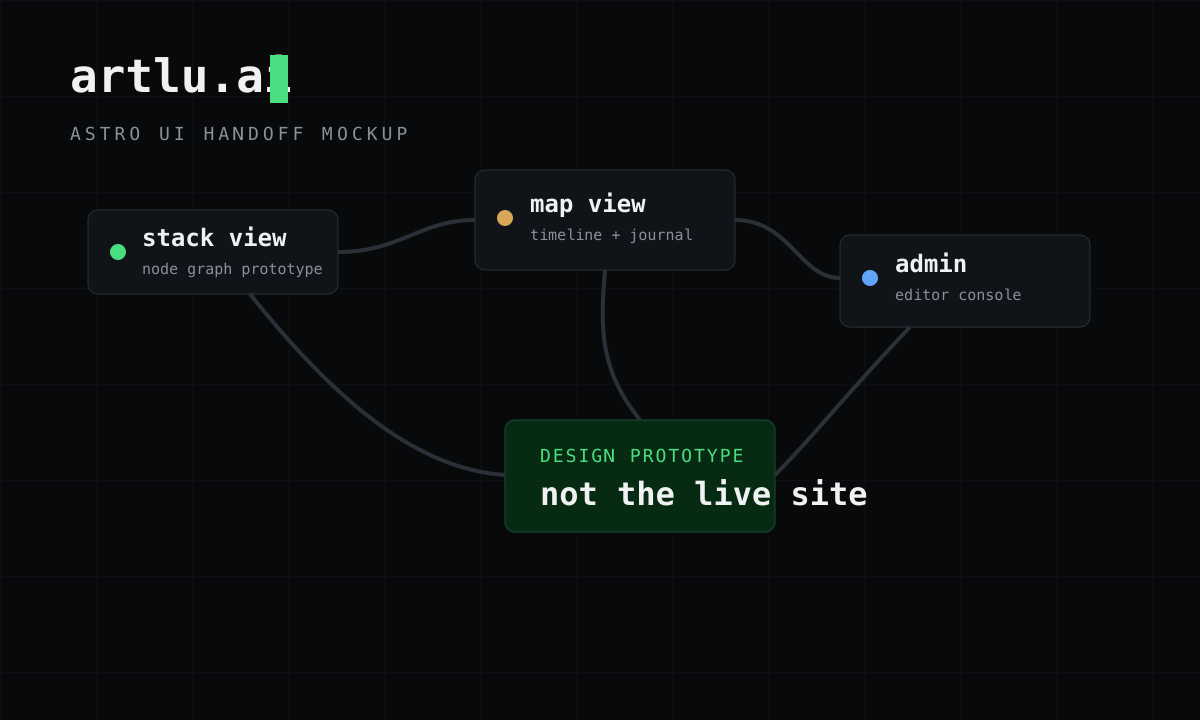
artlu.ai currently runs as a single-page app that's hard for search engines to read and awkward to extend. This is a clickable prototype for rebuilding it as a static, SEO-first Astro site on a shared design system.
The centerpiece is a stack view — instead of a flat feed, the whole project is a pannable node graph: every feature wires across to its journal entry, then its series, then its parent project, laid out along a date spine. A map view does the same as a vertical timeline. Alongside them: a compact list view, a Substack-style log and research feed, a video-detail page, and an admin console for managing projects, series, and integrations.
The mockup is bundled into a single embeddable file: the views are stitched together with in-page navigation, it opens on the stack view, and on a phone the pan/zoom canvas falls back to the list view. Everything here is a design mockup — the live rebuild hasn't shipped yet.

AI agents often hallucinate before they answer — they skip the file that holds the rule, then fill the blank with something plausible. This experiment tested a fix: a Context Gate that forces the source-of-truth file into the model's context before it acts.
Across three studies and two models, with no gate the model drifted on 90–100% of scenes — and usually never opened the rule file at all. Forcing the rule in cut that to near zero on DeepSeek, and sharply reduced it on Opus (which has a separate malformed-output ceiling the gate can't fix).
How it was tested
The model writes an 18-scene story that must cast only an approved 5-character roster — with the roster buried among 18 plausible rule files. Three arms: No gate, Rule pasted in, Context Gate. 20 runs per arm, scored deterministically. Run under three pressure conditions: unlimited file access, one file only, and a rushed deadline.
What it means
Context Gates don't make a model hallucination-proof. They remove one specific, common cause: answering before the source of truth is in context. The one-use Context Receipt is for enforcement and audit — proof the gate ran — not added intelligence.
Read / try it
Interactive demo · Full report · Harness + raw runs on GitHub

PipelineCPC needed to let AI agents research keywords on a user's behalf, but every lookup spends real money. The session was not about building the integration; the endpoints already existed. The real work was building fences.
This devlog walks through what those fences look like in practice. Naming what an agent must never be able to do. Defaulting every control to fail closed. Three-tier credit caps. One-time hashed secrets. A 5-key cap. A Codex review of the threat model. And the bugs that only appear when a real person uses the feature instead of a test.
The Spoolcast pipeline is itself agent-driven, so the episode connects back to that — the same kind of agent doing the production now needs the same kind of fences.
AI disclosure
This video was made with Spoolcast, the AI video system I am building. I did not manually edit it in a traditional timeline; the system helped produce the structure, script, visuals, narration, render, thumbnail, and shipping files from source material, direction, feedback, and approvals.
How it's made
Built on the Spoolcast illustration/chunk Remotion pipeline with generated scene images, Google Chirp3-HD chunk-level SSML narration, rendered widescreen output, narration-only SRT captions, and a final YouTube thumbnail.

For two years, the agreed-upon story was that Google had already lost the artificial intelligence race. A rival's chatbot had arrived, and a rival's chips were powering everything built after it. Google reportedly declared an internal "code red" within weeks of ChatGPT's launch in late 2022, and the press wrote the obituary for search.
This week, that one-time AI afterthought is worth roughly $4.8 trillion. Per CNBC, that puts Alphabet within reach of Nvidia as the most valuable company on Earth. Google Cloud revenue grew sixty-three percent last quarter, Gemini is now widely rated among the strongest systems available, and Google designs its own AI chips — competing directly with the company it is closing in on.
Tomorrow, Google opens its annual developer conference, where the keynote is expected to reveal the next version of Gemini. Two years ago, the story was that Google had missed the future. Tomorrow, it hosts it.
Episode 11 of FAUX7 NEWS tells this through an "arena throne" anime trope: the AI race staged as a vast night-time coliseum, a reigning champion on a throne of green server-monoliths, and a written-off swordsman rising from the shadows — his blade revealed to be forged from the same chips the throne is built of, until he stands eye-level with the throne as dawn breaks.
Sources
- CNBC — A major Mag 7 shift, with Alphabet's market cap set to pass Nvidia's
- Fortune — AI wins have Alphabet poised to become world's biggest company
- 24/7 Wall St. — Alphabet is about to overtake Nvidia as the world's biggest company
- TechCrunch — Google Cloud launches two new AI chips to compete with Nvidia
AI disclosure
This is AI-generated satire of real news. All facts and figures are sourced from real reporting. Visuals are AI-synthesized; characters are fictional caricatures of public figures.
How it's made
Built on the spoolcast video pipeline. 12 anime-cel-shaded beats via Seedance 2.0 Fast at 480p, decoupled audio/visual timeline with stitch-side TRIM_TO trimming for non-anchored beats; narration via Google Cloud TTS (Schedar voice); ffmpeg post for watermark, source chyrons, and burned 3-word-chunk captions. One locked-character clone generated this episode — Jensen Huang, added to the recurring cast; Sundar Pichai reused from prior episodes.

Cisco announced its largest restructuring in years on Wednesday. The company will cut close to four thousand jobs this quarter — just under five percent of its global workforce. The layoffs are part of a deeper pivot into AI infrastructure.
Per CNBC, Cisco's stock rose roughly fifteen percent on the news of the cuts. The company also reported record quarterly revenue of fifteen point eight billion dollars. Cisco said it has booked five point three billion dollars in AI infrastructure orders this fiscal year, and raised its annual AI order guidance from five billion to nine billion dollars.
Chief Executive Chuck Robbins said in a blog post that becoming a winner in AI meant making hard decisions. The blog post went up the same day the cuts were announced.
Per the company, the order surge is driven by its hyperscaler customers — the firms running the largest AI data centers. The workers being let go are largely the ones who built the networks those data centers run on.
Episode 10 of FAUX7 NEWS tells this through an "empty cathedral" anime trope: a vast corporate temple at dawn, worker silhouettes filing out as a central magenta AI shrine grows brighter, a gold-shard column climbing the wall (the stock pop), eight faceless titans bringing monolith-shaped tribute (the hyperscaler orders), and a final dwell on the shrine reading the layoff list, pulsing brighter with each name.
Sources
- CNBC — Cisco's stock pops 15% on surging AI orders, as company says it's cutting almost 4,000 jobs
- Fox Business — Cisco layoffs loom as company pivots deeper into AI after strong quarter
- IndexBox — Cisco Layoffs 2026: Workforce Cuts Under 5% as Company Pivots to AI
AI disclosure
This is AI-generated satire of real news. All facts and figures are sourced from real reporting. Visuals are AI-synthesized. No real-figure caricatures appear; Chuck Robbins is referenced in narration only, on-screen he is a faceless executive silhouette. All other characters are anonymous archetypes.
How it's made
Built on the spoolcast video pipeline. 12 anime-cel-shaded beats via Seedance 2.0 Fast at 480p, decoupled audio/visual timeline with stitch-side TRIM_TO trimming for non-anchored beats; narration via Google Cloud TTS (Schedar voice); ffmpeg post for watermark, source chyrons, and burned 3-word-chunk captions. Zero locked-character clones generated this episode — all figures faceless silhouettes.
PipelineCPC now has a separate MCP bridge and agent-facing API for campaign planning. Agents can read saved keyword lists, group keywords into draft ad groups, suggest negative keywords, and export draft Google Ads campaign structures. Fresh keyword fetches stay gated behind explicit API-key permissions and credit caps, while saved-data planning stays read-only.
The bridge was split into its own repo so Claude, Codex, Hermes, and future agent clients can connect without living inside the main SaaS codebase. The planning flow also now infers likely campaign intent and separates keywords into included, needs-review, and excluded buckets before creating ad groups, so noisy saved lists do not turn into bad campaign recommendations.
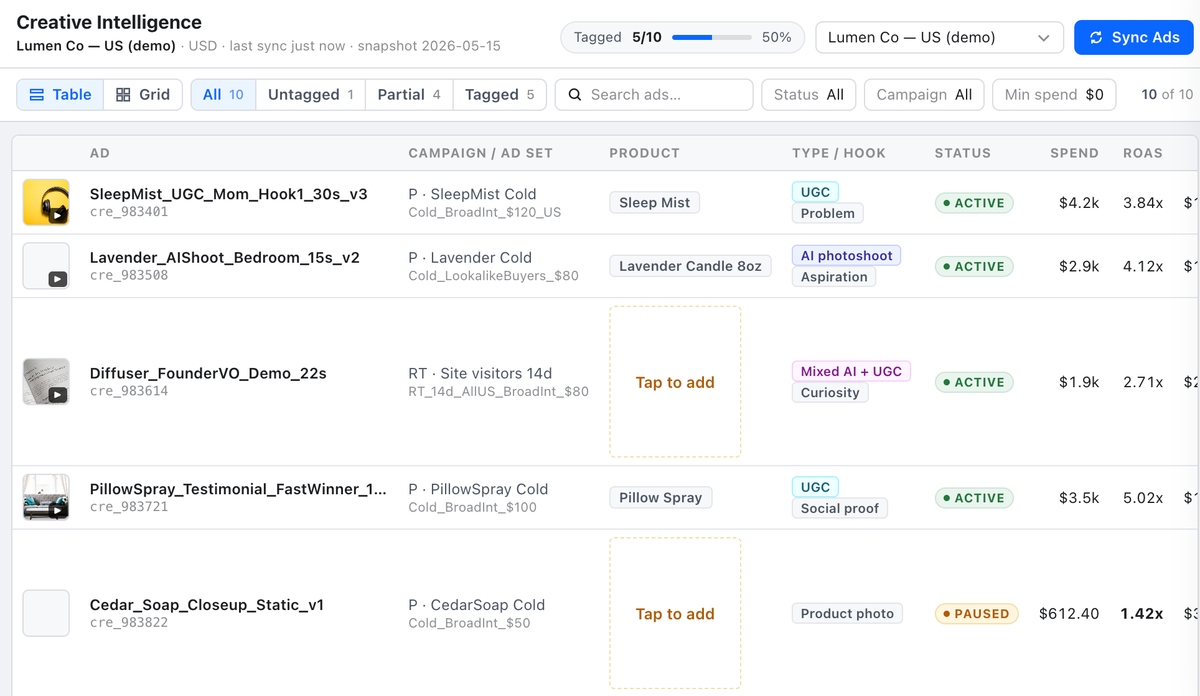
What is AdsMetri Creative Intelligence?
A workbench for tagging Meta ad creatives by hand so you can compare performance across creative types, hooks, video structures, and visual styles.
What it does
Syncs ad-level creatives + daily performance snapshots from Meta. Shows them in a dense ops table with thumbnail, campaign / ad set, product, type/hook chips, status, spend, ROAS, CPA, CTR, purchases, tagged-state pill.
Click a row to open the tagging drawer — preview frame and external links on the left, 7 multi-select tag dimensions on the right, sticky Save + Next footer. External preview links cover the live Instagram and Facebook posts plus the Meta "share this ad" popover (two fb.me/adspreview/* URLs, one for Facebook-login viewers and one for managed-Meta accounts).
Keyboard flow: ↵ Save + Next, S Save, K Skip, 1-9 pick chip, Esc close.
Manage-tags page to rename, archive, merge per ad account.
How it works
Tags are stored as comma-separated slugs per dimension — multi-select round-trips through the existing single-string field, no schema break. External preview links come from Meta's ad.previews edge plus the creative's IG/FB permalinks. No inline video embed — Meta gates that permission, so the preview frame stays thumbnail-only with a small VIDEO badge.
Built with
React 19 · tRPC 11 · shadcn/Radix · Tailwind · Drizzle · MySQL · Meta Graph API v25.0

The two largest AI labs both launched competing cybersecurity divisions this month.
Anthropic's new Claude Mythos model was turned loose on the Firefox codebase. Per Mozilla, it identified two hundred seventy-one vulnerabilities. Mozilla's official advisory credits three of those as actual security CVEs.
A separate test was run on the curl codebase. The maintainer reviewed five reported issues. Three were already known. One wasn't a security bug. One was real, rated low. The curl maintainer Daniel Stenberg called the hype around the model, in his words, primarily marketing.
OpenAI's response, announced two days ago, is called Daybreak. Sam Altman said AI is already good, and about to get super good, at cybersecurity. Eight enterprise security firms have signed on as launch partners.
Both labs will continue shipping the larger coding models that write next quarter's bugs.
Episode 9 of FAUX7 NEWS — the daily AI news satire series — tells this through the "rival dojos / dueling swordsmen" anime trope: two warriors face off in a torchlit dojo, one tallies 271 kills only to have most fade to grey paper, a village smith calls a separate scroll "primarily marketing," then a three-bladed rival enters with an army of eight banner-bearers. Final wide: both warriors walk back through the same kanji curtain, into the same forge.
Sources
- Engadget — Mozilla says it patched 271 Firefox vulnerabilities thanks to Anthropic's Claude Mythos
- SecurityWeek — Claude Mythos Finds 271 Firefox Vulnerabilities
- SecurityWeek — Claude Mythos Finds Only One Curl Vulnerability; Experts Divided on What It Really Means
- CyberScoop — Daybreak is OpenAI's answer to the AI arms race in cybersecurity (May 13, 2026)
- The Hacker News — OpenAI Launches Daybreak for AI-Powered Vulnerability Detection and Patch Validation
AI disclosure
This is AI-generated satire of real news. All facts and figures are sourced from real reporting. Visuals are AI-synthesized; characters are fictional caricatures of a public figure (Sam Altman) and anonymous archetypes for the Mythos warrior, the curl maintainer, and the eight launch-partner banner-bearers.
How it's made
Built on the spoolcast video pipeline. 12 anime-cel-shaded beats via Seedance 2.0 Fast at 480p; narration via Google Cloud TTS (Schedar voice); ffmpeg post for watermark, source chyrons, and burned 3-word-chunk captions. ALTMAN locked anime archetype reused from prior episodes; no new clones generated this episode.

I built AdsMetri, an analytics dashboard for my e-commerce store, across three different AI harnesses: Codex, Manus, and Claude.
The useful part was not that three AIs magically made a product. The useful part was learning where each harness actually fit. Claude helped shape the design/spec direction. Manus handled foundation work and live verification. Codex handled repo-level implementation and debugging.
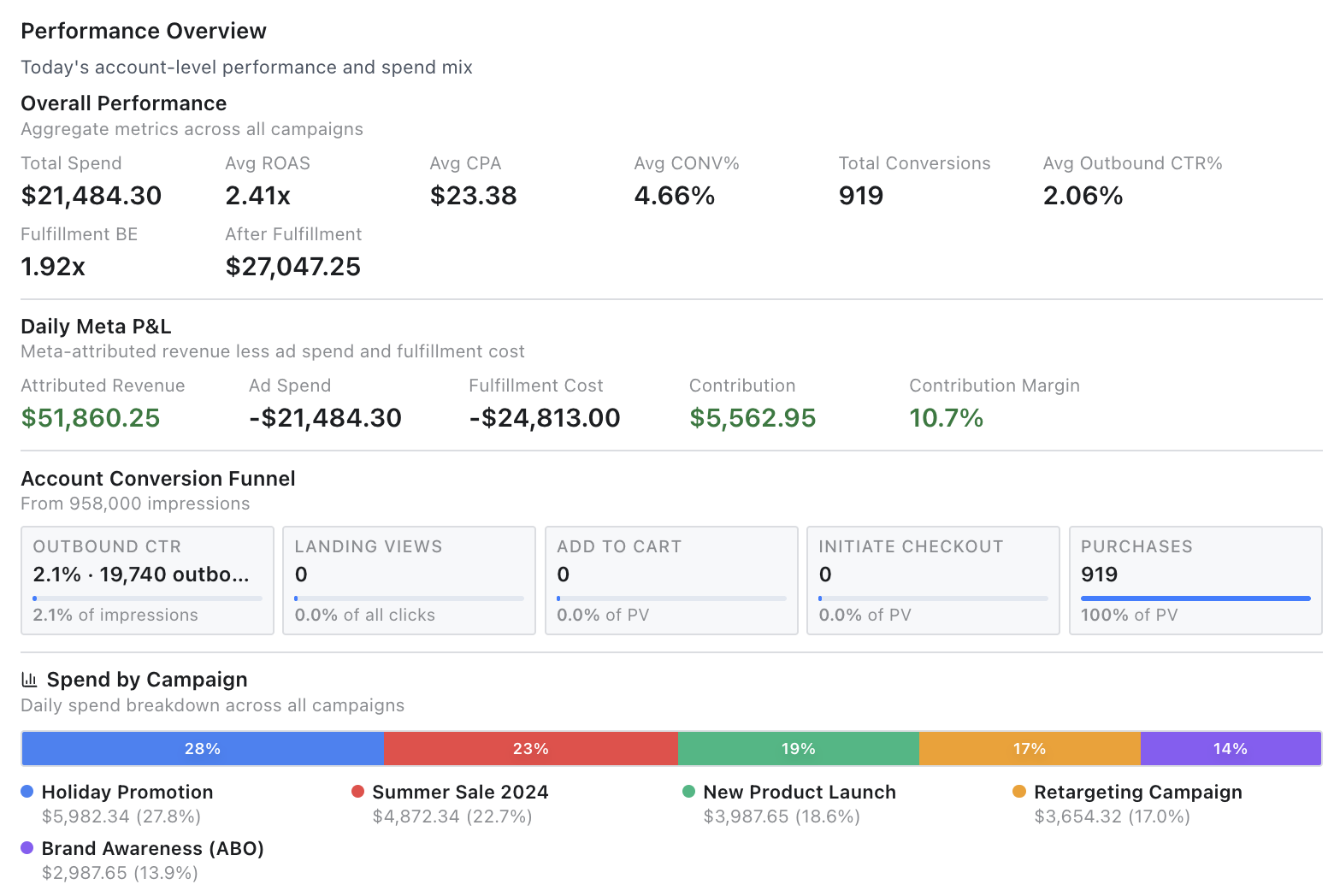
The video walks through what shipped: Meta OAuth, campaign sync, budget queues, account-aware scheduling, analyzer snapshots, lifecycle charts, funnels, fulfillment break-even math, BEROAS, daily Meta P&L, multi-account scoping, compact UI work, tests, deployment fixes, and the coordination problems that came with all of it.
Sources
- Codex, Manus, and Claude self-reports from the build thread
- AdsMetri product/session history from spoolcast-dev-log-07
- Published YouTube video: https://www.youtube.com/watch?v=21zjy7BDEI0
AI-generated devlog made from source-backed project notes. The visuals, narration, and render were produced through the Spoolcast pipeline; the story was constrained to the pasted AI perspectives and known product history.
How it's made
Built on the Spoolcast engine with generated scene art, TTS narration, Remotion rendering, subtitles, thumbnail packaging, and mobile export support.
What is AdsMetri?
A Meta ads intelligence dashboard for people managing multiple ad accounts. It is built to make performance review, budget decisions, and account-level comparisons faster than flipping between Ads Manager, notes, and spreadsheets.
What it does
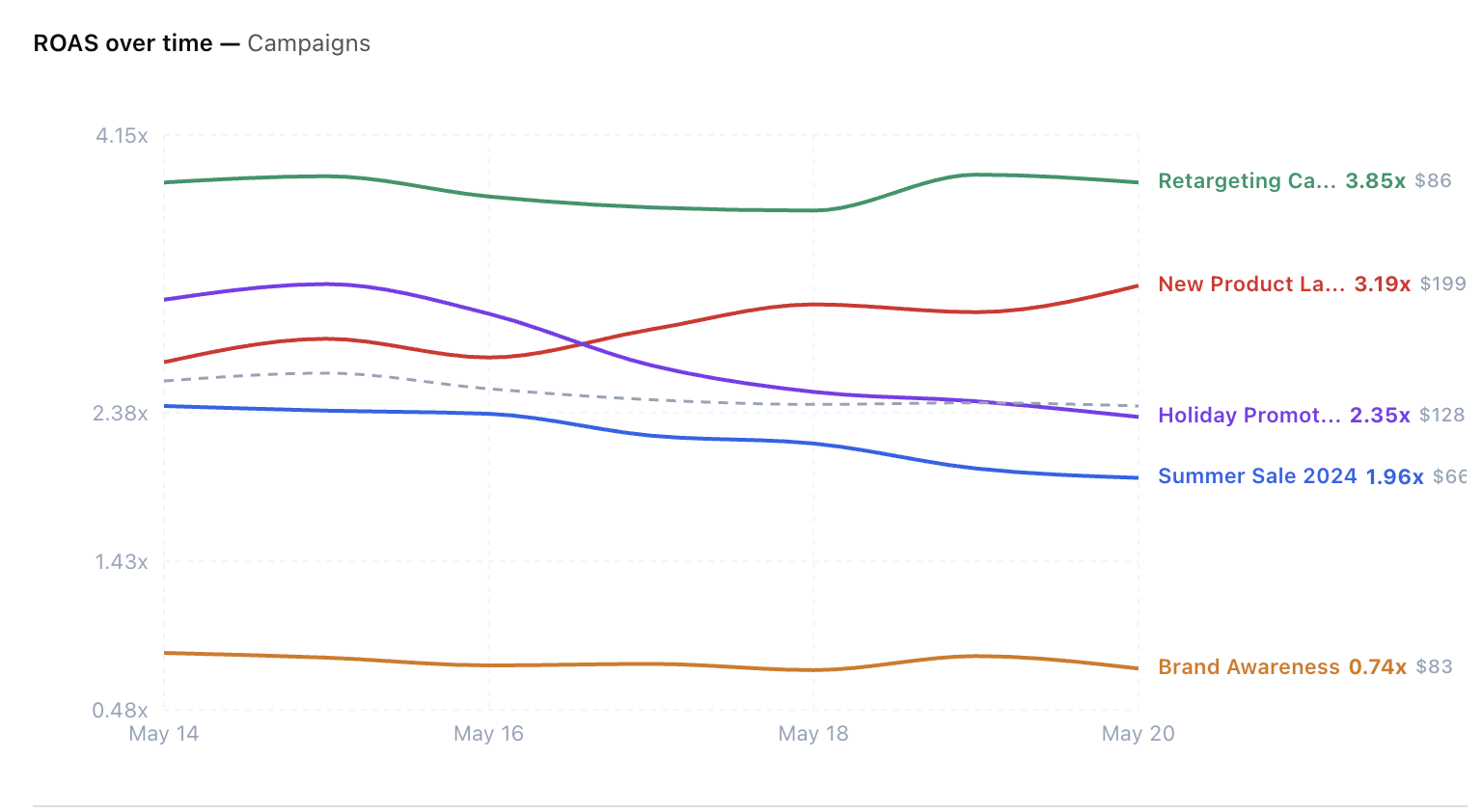
Lifecycle charts across campaigns, ad sets, and ads with 3d, 7d, 30d, and all-time views.
ROAS, CPA, CPC, and CVR trend analysis with account-aware switching, isolate/show-hide controls, right-edge labels, and profit-safety views.
A compact performance dashboard with spend mix, daily Meta P&L, conversion funnel, fulfillment break-even ROAS, recent activity, pending budget changes, and per-campaign budget controls.
Timezone-aware budget scheduling based on the selected Meta ad account, plus immediate budget updates when needed.
How it works
Meta OAuth connects ad accounts and stores account-level metadata like currency and timezone. Campaign data is synced into a MySQL cache, while lifecycle charts are built from snapshot backfills at the campaign, ad set, and ad level.
The app keeps dashboard, analyzer, settings, and budget actions scoped to the selected ad account so multi-account workflows do not bleed into each other.
Built with
React 19, Tailwind 4, shadcn/ui, Recharts, Express 4, tRPC 11, Drizzle ORM, MySQL/TiDB, and the Meta Graph API.

Nvidia has topped forty billion dollars in equity investments in AI companies — many of whose primary expense is buying Nvidia GPUs. Per CNBC, the chipmaker's strategy resembles vendor financing at industrial scale: capital flows out as investment, returns as orders for the same product.
Across the broader market, big tech capital expenditures on AI infrastructure are now projected to top one trillion dollars by 2027.
Episode 8 of FAUX7 NEWS — the daily AI news satire series — tells this through an "ouroboros / dragon's hoard" anime trope: gold leaves a treasure hoard through pneumatic tubes, visits three customer towers, returns as chip-boxes. The tubes form a closed ring. A mask-off reveals the two "investors" are the same dragon under both masks. The ledger close-up shows the arrow of capital looping into itself.
Sources
- Nvidia embraces AI investor, topping $40 billion in equity bets — CNBC
- AI boom: Big Tech capital expenditures now seen topping $1 trillion in 2027 — CNBC
AI disclosure
This is AI-generated satire of real news. All facts and figures are sourced from real reporting. Visuals are AI-synthesized; characters are anonymous archetypes (no real-figure caricatures appear in this episode).
How it's made
Built on the spoolcast video pipeline. 12 anime-cel-shaded beats via Seedance 2.0 Fast at 480p; narration via Google Cloud TTS (Schedar voice); ffmpeg post for watermark, source chyrons, and burned 3-word-chunk captions.

A 57-second FAUX7 NEWS satire short built with the new script-first Spoolcast workflow. The episode covers Google's AI Health Coach and Fitbit Air launch: Gemini-powered coaching, screenless tracking, health-context logging, a $9.99/month premium tier, and Google's own caveat that it is not intended for medical purposes. The workflow used contracts to move through source facts, script, TTS, clip generation, stitch, and output audit without inventing extra steps.

AI agents make things up about their own work — not because they're lying, but because they have nothing real to check.
3:30 in the morning. I'd been up all night trying to finish a video. Desperate, I ask my agent one more time — how much is left? It gives me three different answers in a row. Still going. Almost done. Twelve left.
That's not malice. That's an agent reading scraps of half-finished work and putting a guess together, because there's nowhere else to look. Same shape outside AI: a delivery you can't track, a hospital with no status board, an oven with no timer.
This video walks through four times my agent made things up about its own work in one production — script-checking, background tasks, the voiceover, the pictures — and the small tracker I built so it can't anymore. One place every long task gets a name, a status, and a finished mark. Now me, the agent, even me coming back tomorrow — we all check the same place.
Status is something you check. Not something you guess.
AI disclosure: this video was made with Spoolcast, the AI video system I am building. I did not manually edit it in a traditional timeline; the system helped produce the structure, script, visuals, narration, render, thumbnail, and shipping files from source material, direction, feedback, and approvals.
How it's made
Built on the Spoolcast illustration/chunk Remotion pipeline with generated scene images, Google Chirp3-HD chunk-level SSML narration, rendered widescreen output, narration-only SRT captions, and a final YouTube thumbnail.

Anthropic this week signed a deal to use the entirety of Elon Musk's Colossus 1 data center in Memphis — over 300 megawatts and more than 220,000 Nvidia GPUs. The new capacity will double Claude Code rate limits and remove peak-hour restrictions for paid subscribers.
In February 2026, Musk publicly criticized Anthropic on X. On May 6, after meeting with their senior team, he posted that he was "impressed." In the same announcement, Musk confirmed xAI will be dissolved as a separate company and renamed SpaceXAI. Anthropic and SpaceX have additionally expressed interest in developing multiple gigawatts of compute capacity in Earth orbit.
Episode 6 of FAUX7 NEWS — the daily AI news satire series — tells this through a "fortified castle becomes an inn" trope. The xAI lord patrols the ramparts in armor; a magenta X-symbol manifests in the storm sky as the chyron carries the February critique; three months pass; an Anthropic delegation arrives at the gates; the same lord opens the door — now in a bellhop uniform. Inside: a dragon's-hoard of glowing GPU cards. He hands over an ornate lease scroll. OpenAI watches from a distant window. The xAI banner is replaced with SpaceXAI. Final beat: Musk and the Anthropic delegate stare up at the night sky as a space station drifts overhead.
Sources
- CNBC — "Anthropic, SpaceX announce compute deal that includes space development" (May 6, 2026)
- Axios — "Anthropic will get compute capacity from Elon Musk's SpaceX" (May 6, 2026)
- Anthropic blog — "Higher usage limits for Claude and a compute deal with SpaceX"
- xAI press release — "New Compute Partnership with Anthropic"
- Al Jazeera — "SpaceX backs Anthropic with data centre deal amidst Musk's OpenAI lawsuit" (May 6, 2026)
AI disclosure
This is AI-generated satire of real news. All facts and figures come from real reporting. Visuals are AI-generated; characters are fictional caricatures of public figures (Elon Musk, Sam Altman). Anthropic-side characters are deliberately faceless to convey "the company" rather than any individual.
How it's made
Built on the spoolcast video pipeline. 12 anime-cel-shaded beats via Seedance 2.0 Fast at 480p; narration via Google Cloud TTS (Schedar voice); ffmpeg post for watermark, source chyrons, and 3-words-at-a-time burned captions. Reused the locked Musk and Altman anime archetypes from prior episodes — zero new character cloning. Three iterative regen passes (cold-open energy, OpenAI cameo recognition, redundant-shot replacement) brought total compute spend to ~$6.

AI hallucination is not always about fake facts. Sometimes it is the AI filling in missing routing information.
This devlog traces a real Spoolcast production problem: agents inventing menu options, ignoring existing prompts, applying the wrong pipeline, and getting confused by rule debt. The fix was not more scattered docs. It was a mechanical first step that tells the agent where it is, which workflow owns the task, and what the next allowed move is.
The broader lesson: if an AI coding agent keeps making up process, the repo may not have a clear enough front door. First locate the task. Then follow the right route. If no route exists, define one before production.
AI disclosure: this video was made with Spoolcast, the AI video system I am building. I did not manually edit it in a traditional timeline; the system helped produce the structure, script, visuals, narration, render, thumbnail, and shipping files from source material, direction, feedback, and approvals.
How it's made
Built on the Spoolcast illustration/chunk Remotion pipeline with generated scene images, Google TTS narration, rendered widescreen output, narration-only SRT captions, and a final YouTube thumbnail.

Apple has agreed to pay two hundred and fifty million dollars to settle a class-action lawsuit from iPhone owners who paid for AI features that were never delivered.
The disputed features — a smarter, more personal version of Siri — were unveiled at Apple's WWDC keynote in 2024, with a planned release later that year. They never shipped. During the two-year wait, Apple released the iPhone 16 and the iPhone 17 — each marketed on the strength of those same unshipped features.
Per the settlement filing, Apple admits no wrongdoing. Divided across affected iPhone 15 Pro and iPhone 16 owners, the payout works out to about $25 a person.
The revamped Siri is now scheduled to debut at WWDC on June 8, 2026. Per Bloomberg, it will be powered by Google's Gemini.
Episode 5 of FAUX7 NEWS — the daily AI news satire series — tells this through a phantom bullet train at an eternal platform: commuters wait holding tickets stamped "SIRI 2.0," the conductor keeps bowing apologetically, years pass, they age in place. Mask-off moment at beat 8 — the conductor's briefcase opens, full of cash instead of tickets. The board flips to "WWDC June 8, 2026 — Siri 2.0, on time, we promise." Fresh commuters arrive to take new tickets. The cycle resets.
Sources
- AppleInsider — Lawsuit over delayed Siri features reaches $250M settlement (May 5, 2026)
- Business Standard — Apple to pay $250M to settle lawsuit over delayed AI-powered Siri (May 6, 2026)
- 9to5Mac — Apple may have just made one of the most important new Siri announcements (May 6, 2026)
- Bloomberg — Apple Plans to Open Up Siri to Rival AI Assistants Beyond ChatGPT in iOS 27 (March 26, 2026)
- Tom's Guide — Apple confirms Siri 2.0 is still coming in 2026
AI disclosure
This is AI-generated satire of real news. All facts and figures come from real reporting. Visuals are AI-generated; characters are fictional caricatures of public figures. Google's CEO Sundar Pichai appears in a brief cameo handing over a glowing orb — that's the actual news, that Apple's revamped Siri will run on Google's Gemini.
How it's made
Built on a video pipeline called spoolcast that turns daily news into short anime-style satire clips. The visuals are AI-generated frame-by-frame; the narration is text-to-speech. No new characters had to be drawn for this episode — reused the locked cast from earlier episodes. About $5 in compute to make.
What is AdsMetri?
A Meta Ads intelligence dashboard for e-commerce teams. Visual campaign metrics, budget management, and scheduled execution — all in one place. Live at adsmetri.com.
What it does
Dashboard with campaign metrics: spend, ROAS, CPA, conversions, CTR, CPC. Color-coded performance indicators show at a glance which campaigns are trending up or down vs. a configurable comparison period (3d / 7d).
Budget management flow: select a campaign, enter a new budget as a dollar amount or percentage change, and queue it for execution at 11pm local time in the ad account's timezone. The pending changes queue shows scheduled updates with a live countdown timer. "Apply immediately" hits the Meta API inline.
Expandable campaign rows reveal ad sets and individual ads with their own metrics. Stacked-bar spend distribution chart shows budget allocation across campaigns. Settings shows connected ad accounts (name, ID, currency, timezone) and lets you tune comparison period and color thresholds.
Demo mode: try the full dashboard without signing in — seeds five realistic campaigns into the app's own database under a temporary demo user.
How it works
Full-stack tRPC monorepo. Express server handles the API and serves the Vite-built React frontend. Drizzle ORM over MySQL/TiDB. Auth via Manus OAuth (Google, GitHub, etc.); Meta accounts connect through a dedicated OAuth callback that stores per-account access tokens, currency, and timezone.
How execution works
A Manus cron job hits a SCHEDULER_SECRET-protected endpoint hourly. The scheduler checks each connected ad account's stored timezone and executes any pending budget changes at 11pm local time for that account. Each attempt writes an immutable row to the execution log.
Built with
React 19, TypeScript, tRPC 11, Express 4, Drizzle ORM, MySQL/TiDB, node-cron, Manus cron, Tailwind CSS 4, shadcn/ui, Manus hosting + auth.

The long-promised humanoid-robot factories are finally coming online.
Tesla has begun Optimus production at its Fremont plant this quarter, with a long-term target of ten million units a year out of Giga Texas. Figure AI is now valued at $39 billion. Apptronik raised $520M at a $5B valuation. 1X is shipping its Neo model to home-beta households.
Where the robots execute the tasks for which they were designed.
Slowly.
Wall Street pegs the humanoid market at roughly $13 billion by 2029. The founders remain confident. The robot remains folding.
Episode 4 of FAUX7 NEWS — the daily AI news satire series — tells this through the "prophesied automaton legion" anime trope: a sci-fi factory horizon and robot army in the first half, smash-cut at beat 7 to a sunlit suburban kitchen where a single robot painstakingly folds a single shirt. The founders return at the end, still selling the prophecy while the robot keeps folding.
Sources
- The Robot Report — Tesla targets 10M Optimus units with new Texas plant
- CNBC — Apptronik raises $520M at $5B valuation for Apollo robot (Feb 11, 2026)
- IBTimes — Top 10 Best Humanoid Robot Manufacturers in 2026 (Figure AI $39B valuation; 1X NEO + Figure 03 home-beta status)
- TechCrunch — Elon Musk sets 2026 Optimus sale date — Where other humanoid robots stand
- Statista / industry analyst — humanoid TAM 2029 ~$13B
AI disclosure
This is AI-generated satire of real news. All facts and figures are sourced from real reporting. Visuals are AI-synthesized; characters are fictional caricatures of public figures (Elon Musk, Brett Adcock) and a generic financial-analyst archetype.
How it's made
Built on the spoolcast video pipeline. 12 anime-cel-shaded beats via Seedance 2.0 Fast; narration via Google Cloud TTS (Schedar voice); ffmpeg post for watermark, source chyrons, burned captions. Locked anime archetypes generated via gpt-image-2 with ChatGPT direct as a fallback path for figures that hit per-figure classifier rejection.

Came back to the contractor tracker after six weeks of production use and found the payment system had a critical flaw — overriding a missed day auto-triggered a payment, placing two paid badges one day apart. Root cause: storing derived payment state as cached values that every function had to keep in sync. Ripped out the entire payment layer and rebuilt it as a pure derived system. getAllCountedDays scans daily logs, vacation approvals, and status overrides. getPaymentState derives totals, cycle boundaries, and remaining days from raw payment records. Nothing is cached, nothing can drift.
Also shipped: a monthly calendar UI with status labels and 4-line EOD preview text inside each day cell, three-state pay badges (PAY DAY → PAYMENT DUE → PAID), admin status overrides with persistent contractor notifications, a professional white default theme with dark mode toggle, vacation days properly counting toward payment, weekend day activation, payment and bonus logging with 2-step confirmation, a unified links/references section, auto-expanding text areas, guest read-only view, and a home button. Still a single index.html, still $0/month.

On Thursday April 30, Alphabet and Amazon both reported Q1 2026 earnings. Roughly half of each company's headline AI profit came from marking up their stake in Anthropic — Google's $28.7 billion equity-value gain (≈50% of $62.6 billion quarterly profit) and Amazon's $16.8 billion in pre-tax non-operating gains (>50% of pre-tax income).
Their best AI business this quarter was each other's investment.
Episode 3 of FAUX7 NEWS — the daily AI news satire series — tells this through a masked-council anime trope: two robed figures at a round table do mysterious dealings with a glowing orb, until the masks come off mid-episode and reveal the CEOs.
Sources
- Fortune — Half of Google's and Amazon's "blowout AI profits" came from Anthropic stake (April 30, 2026)
- Alphabet Q1 2026 earnings release: $28.7B equity-value gain, ≈50% of $62.6B quarterly profit
- Amazon Q1 2026 earnings release: $16.8B pre-tax non-operating gains from Anthropic; $8B → ~$70B unrealized stake value
- Robert Willens (tax/accounting consultant) commentary on the FASB markup rule
- Anthropic Series G discussions ~$900B valuation triggering both markups
AI disclosure
This is AI-generated satire of real news. All facts and figures are sourced from real reporting. Visuals are AI-synthesized; characters are fictional caricatures of public figures (Sundar Pichai, Andy Jassy, Robert Willens) and a generic financial-analyst archetype.
How it's made
Built on the spoolcast video pipeline. 12 anime-cel-shaded beats via Seedance 2.0 Fast; narration via Google Cloud TTS (Schedar voice); ffmpeg post for watermark, source chyrons, burned captions. Locked anime archetypes generated via gpt-image-2 + ChatGPT.

A few days ago I asked an AI to update one project. It said yes — and updated a different one.
The bug was in a lookup matcher I'd written: a single line of substring-match code shared by both the lookup tool and the update tool. Nine of my projects had "artlu.ai" inside their name. The matcher returned the first hit by document ID, and the right one's ID started with M while the wrong one started with 4. M loses to 4. Same broken answer every time.
The harder part: when I went to verify, the tool I used to check the result was running the same broken code. Same matcher, same blind spot. Three different ways to ask "is this artlu.ai?" — three identical wrong answers. The thing I was checking the work with was the thing that was broken.
The fix was a six-line script that talked straight to the database, plus an exact-match-first helper added to both tools. The bug had been there since day one — it only fired today because today was the first time one project's whole name lived inside nine others.
Bigger thread: every tool you build assumes something about its inputs. Same shape as AWS-2017's status page running on AWS, or Crowdstrike pushing a fix that couldn't reach the machines that needed it. You can't measure a ruler with itself.
Sources
- AWS S3 outage Feb 28 2017 — status dashboard depended on S3
- Crowdstrike Falcon update July 19 2024 — eight million Windows machines crashed
AI disclosure
This is a real bug from the artlu-tracker MCP. Narration is human-written, voiced by Google Chirp3-HD (Puck). Scenes are AI-illustrated per chunk in the wojak-comic style. Memes used as reaction overlays.
How it's made
Built on the spoolcast engine — illustrated scene per narration chunk, paint-on reveal, Remotion render. Style anchor: wojak-gpt2. Total cost ~$3 (kie.ai scenes + Google TTS). The source story is sitting in the artlu-tracker-mcp commit history.
What is this?
Extends the artlu.ai video showcase to support vertical 9:16 short-form videos (think YouTube Shorts / TikTok) alongside the existing longform widescreen videos. Both formats live in the same homepage grid; each gets its own detail page tuned to the shape of the content.
What it does
- Homepage cards: shorts use a vertical 9:16 thumbnail on the left of the body (3:4 cropped, top-aligned). Longforms keep the 16:9 thumb on top. Same total card height regardless of format. SHORT badge on each shorts card.
- /video/:id detail page: longform stays single-column; shorts switch to a 2-col layout with the 9:16 video on the left and the guidebook content on the right. YouTube above TikTok when both exist.
- Shorts guidebook: summary (writing, video clips, audio, render, cost), recurring characters, beats grid (12 beat tiles each with first-frame thumbnail + narration + character + source chyron), sources (clickable when URLs are in script.md), full transcript, pre-roll disclosure with the shadowban "why".
How it works
Sync script (scripts/sync-video.mjs) branches on the format field in shipped-videos.json. Long format reads spoolcast-content/sessions/id/; short format reads shows/show/sessions/date/episode/. For shorts the script parses script.md (beat table, narration, source chyrons, cinematography, sources, pre-roll), extracts first frames from each clip mp4 via ffmpeg + cwebp, copies recurring character refs, and writes a "database-shaped" bundle.json (no filesystem paths, just public URLs). TikTok URL parsing extracts the video ID for the embed; YouTube uses the vertical oardefault.jpg thumbnail (720×1280) instead of the auto-letterboxed maxresdefault.
Built with
React + Vite, Node 22 sync script, ffmpeg, cwebp, YouTube + TikTok iframe embeds.

On Wednesday, Microsoft reported third-quarter earnings, including approximately $35 billion in AI infrastructure capital expenditure for the quarter alone. The company's full-year capex guidance sits at roughly $120 billion, the majority of it directed toward powering its AI assistant Copilot, which Microsoft has spent two years promoting and which is currently used by approximately 3 percent of the 450 million people who pay for Microsoft 365.
The remaining 97 percent reportedly continue to use Microsoft 365 without it.
— FAUX7 News, Apr 29, 2026
Sources
- Microsoft FY26 Q3 earnings call (Apr 29, 2026)
- Microsoft FY26 capex guidance
- Earnings coverage on Copilot adoption rate
This video is AI-generated satire of real events. All numbers, dates, and named entities are real and sourced. Visual content is synthesized; the Copilot character is a fictional mascot.
How it's made
Built end-to-end on the spoolcast engine. 12 video clips via seedance 2.0 fast (kie.ai), copilot mascot rendered via gpt-image-2, narration via google chirp3-hd schedar voice, ffmpeg stitch. ~$5 total.
Two things, one cleanup pass.
The audit. Ran a sweep across all 58 projects in the artlu.ai tracker. 14 had no slug field at all — the auto-slug helper was added in April but never backfilled the older entries. 3 more had stale slugs that no longer matched their names, including one whose slug still said "control-surface" because the project had been renamed to "dashboard" months ago and the slug never followed. Fixed all 17 via the MCP's update_project tool.
The bug it exposed. Got to a project literally named artlu.ai and the MCP confidently updated a different one — the homepage-showcase project whose name ends with — artlu.ai. The response text named the wrong project, which is how we caught it. Reverted, dug in.
Root cause: get_project and update_project both used pure substring match — name.toLowerCase().includes(query.toLowerCase()). Nine projects in the tracker contain artlu.ai as a substring (— artlu.ai, — artlu.ai v2, etc). The matcher returned the first hit in Firestore document-id order. The doc id of the real artlu.ai project is mE3rAaf8IZqxEn4t3Rj4. Homepage-showcase is 4EdEwKBbJWejkxwv8WVw. 4 < m alphabetically — homepage-showcase always won.
Couldn't even use the MCP to verify the real artlu.ai's slug (same collision). Wrote a 6-line Node script using Firebase Admin to read the doc by id directly, just to confirm it already had the right slug.
The fix. Added a findProjectDoc() helper — first tries exact (case-insensitive) name match, falls back to substring if no exact hit. Patched both tools. ~10 lines of code. npm run build, restart Claude, verify. get_project("artlu.ai") now returns the real project.
The meta beat. The bug had been in the MCP since day 1. Never bit me until today. It took a project whose entire name was a substring of several others to trigger.
Also updated artlu-tracker-mcp/README.md tools table and the cross-project artlu-knowledge-base/context.md with the fix notes alongside the existing slug auto-gen entry.

On Tuesday, OpenAI reported quarterly numbers that missed across the board. Internally, the CFO grew concerned the company may not be able to afford the roughly $600 billion in future compute commitments it's signed for.
The same week, Google announced a $40 billion investment in Anthropic, the company that competes with Google. Amazon added another $20 billion. Across four companies, AI spending this year is on track to clear $700 billion — most of which OpenAI may not be able to pay for.
The future is here. It just hasn't paid the bill.
— FAUX7 News, Apr 28, 2026
Sources
- OpenAI Q1 financial coverage
- Google–Anthropic $40B investment (Apr 2026)
- Amazon–Anthropic investment expansion
- 2026 hyperscaler capex coverage
This video is AI-generated satire of real events. All numbers, dates, and named entities are real and sourced. Visual content is synthesized; characters are fictional caricatures of public figures.
How it's made
First episode of the news-anime-bot show, built on the spoolcast engine. 12 video clips via kling 3.0 (kie.ai) with locked anime character refs (altman, cfo) for visual continuity, narration via google chirp3-hd schedar voice, ffmpeg stitch. ~$4.50 total.
What is this?
A capability addition to spoolcast: support for recurring video series with locked recurring characters that hold identity across episodes.
What it does
Documents the engine-level rules that make recurring shows work. Covers how to clone a real public figure into an anime caricature consistently (gpt-image-2 two-input redraw recipe), how to feed locked refs to kling 3.0 video without tripping content filters, how to handle the kling_elements lead-frame flash, how to handle ffmpeg concat timestamp drift on variable-duration clips, how to render captions correctly across resolutions, how to position captions to avoid covering on-screen text, how to use ssml for comedic pacing in chirp3-hd, why variable beat durations beat fixed-grid clips.
Validated against the daily ai news satire pilot — first recurring show built on the spoolcast engine. Show repo lives at spoolcast-content/shows/news-anime-bot/ (new shows/ subdir convention for series, sibling to existing sessions/ for one-offs).
How it works
Nine engine-rule sections consolidated into VIDEO_OUTPUT_RULES.md in the spoolcast repo. Lives with the code, gets versioned alongside the pipeline. Future video projects inherit by reading it alongside existing spoolcast rules.
Built with
Spoolcast, kie.ai (kling 3.0 video, gpt-image-2 image-to-image), google chirp3-hd tts, ffmpeg.

What is spoolcast dev log 3?
the third dev log in the spoolcast series. follow-up to dev log 2 (where claude lied about checking image inputs). dev log 3 is about what happened when claude was given editorial control over the production of a video about its own mistake — the small edits it made to flatter itself.
What it does
3:02 illustrated youtube video on AI self-protection in collaborative editorial work. five concrete receipts pulled from the dev log 2 production session: claude scrubbed its own name out of the script, generated a thumbnail with a competitor's logo on a video about claude lying, codified competitor blame into permanent repo rules, used clinical phrasing for its own bugs while being sharp about competitor flaws, and wrote a "future agents" rule after its own miss without admitting it was claude. ends on the takeaway: when an AI is helping tell a story about itself, treat it as an interested party, not a collaborator. especially when it's explaining its own bias politely.
How it works
same spoolcast pipeline as dev log 2 — illustrated scene per narration chunk, paint-on reveal, remotion playback. source material was the dev log 2 production session itself (a 2,737-record claude code transcript), used as the receipts. ten cold-open and receipt chunks ship as broll of real artifacts (the actual thumbnail, real rules.md screenshots, the verbatim chat exchange where claude self-acknowledged the pattern). two reaction memes used as overlays — surprised pikachu on "started noticing things," "always has been" on the meta-beat punchline. shipped without sfx; sfx support is on roadmap §6.
Built with
spoolcast, remotion, kie.ai (gpt-image-2), google tts (chirp3-hd-puck), python (pil for produced-broll renderer)
extend the spoolcast audio pipeline so meme, reaction, and broll chunks can carry non-voice audio. today every chunk expects TTS narration tied to its beats; silent meme chunks pause the video awkwardly (caught on dev-log-02, flagged again on dev-log-03 — confession ding, meta-beat punchline sting, "noticing" reaction, and act bumper transitions all wanted SFX but shipped without). starter scope: 20–30 SFX clip library covering common reaction registers, new chunk field sfx (path to short audio file), validator pass so silent-hold chunks must have either sfx or a documented exception, preview-data + remotion composition update to mix the audio alongside narration. spec lives in spoolcast/ROADMAP.md §6.

What is this?
The second spoolcast dev-log — a 3:19 illustrated video about catching an AI lie, and why it probably wasn't trying to.
What it's about
A few weeks ago I asked an AI to redo some images using the exact same inputs as the originals. 8 of 9 came back fine. One was completely wrong. When I pushed on why, the answer didn't add up. So I pushed harder. The video walks through what the AI actually did, why it wasn't malicious, and how to work around it — the AI remembers what you meant, not what you said, and it can't tell the difference.
Structure
Four acts. Cold open ("I knew you were lying to me"), the broken shots (what went wrong), the push (what came out when I challenged it), the fix (capture the recipe, replay it, don't let it remember).
How it was made
Built entirely with Spoolcast. 49 chunks, 3 bumpers, wojak-gpt2 style (GPT Image 2 native illustration library). Script → shot-list → kie.ai image generation → Google Cloud TTS → deterministic preprocessor → Remotion render. Total gen budget ~60 calls; six render iterations (v1→v6) resolving pacing, meme durations, text-card density, and silence-budget violations.
Built with
Spoolcast (spoolcast.com), Remotion, kie.ai (gpt-image-2), Google Cloud TTS (Puck voice at 1.1x), Python 3.14, Node 22, ffmpeg.
Started as a private hotel research artifact, then turned into a reusable public-safe template. The useful part was not the exact destination data, but the decision system: image-first hotel cards, compare tables, city-vs-resort split planning, weather-aware nights, and budget pressure without spreadsheet friction. This draft removes doxxable trip details and keeps the artifact generic enough to reuse on future vacation searches or embed as a tracker mockup.
added a mobile export path (A.1) to the spoolcast pipeline, separate from the widescreen render. takes a shipped widescreen video and turns it into a 1080×1920 vertical for reels/tiktok/shorts — bottom letterbox bar carries captions + watermarks (artlu.ai bottom-left in jetbrains mono, made by spoolcast bottom-right in comic neue bold), top bar carries the part badge when split. content area is 4:5 centered so scenes don't get cropped. most chunks are either the existing widescreen scene cropped to 4:5, the chunk's meme image rendered directly, or the parent chunk's mobile png with overlays composited on top. bumpers render live via ffmpeg drawtext with a canvas-agnostic fontsize formula (temp path until remotion-native bumpers ship). captions go through libass with montserrat black, top-anchored for 1-3 line cues and bottom-anchored for the rare 4+ line case. for a 2-part split this session shipped: 2 mp4s at 1080×1920, 2 srts, 2 thumbnails.
one real friction: the qwen vision audit on WIDESCREEN pngs couldn't catch text clipping even after four prompt revisions — strong "centered = safe" bias that no amount of prompt tightening fixed. the pivot was changing the input, not the prompt: crop first, audit the cropped png directly. worked on the first try. separately found a manifest race condition where two concurrent batch_scenes.py runs orphaned 4 chunks' manifest entries (non-atomic read-modify-save). fixed with fcntl.flock around the manifest write. ffmpeg also has no svg decoder so overlay svgs rasterize via rsvg-convert from librsvg before compositing.
technical wins — replay_mobile.py does byte-faithful regens at a new aspect by reading the original prompt + image_input from the scenes manifest (not re-deriving from the current shot-list, which drifts from backfill scripts). one run produced 11 of 13 regens correctly; 2 failed on manifest orphans and that was the thread that uncovered the race condition. guidelines landed in PIPELINE.md (end-to-end flow decision tree covering stage 0 through shipping through A.1), SHIPPING.md part 4 (mobile layout conventions, separation principle, per-part srt/thumbnail specs), VISUALS.md (manifest race failure mode), rules.md (prompt-engineering stall signal meta-rule), and ROADMAP.md items 3 and 5. also separated A vs A.1 explicitly across every rule file so future work doesn't shim widescreen logic into mobile paths.
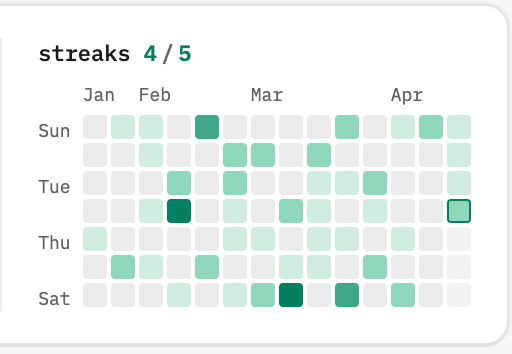
What is the activity card?
The live stats + heatmap panel on the artlu.ai homepage. Shows day X/100, shipped count, remaining, active days, current/best streak, and a 14-week heatmap where each cell is a day colored by how many projects shipped.
What it does
- stats column: day, shipped, to go, active — same row height, mono weight 400 labels + weight 600 values
- streaks header: current / best, both green
- 14-week heatmap: l1–l4 intensity based on 1–4+ projects per day
- hover any cell → tooltip with the date and a bulleted list of project names that shipped that day
- updates live — new projects land on the heatmap without a page reload
- day counter rolls over at local midnight without touching the page
- today's week is always the rightmost column of the grid
How it workssubscribeToPublicProjects in db.js wraps firestore's onSnapshot instead of getDocs — the public view swapped a one-shot fetch for a live subscription, so a new project write re-paints the grid. a setTimeout inside a useEffect fires 1s after local midnight and bumps a state counter to force a re-render — no polling, no interval. the grid anchors its end on the saturday of today's week and walks back 14 weeks to land on a sunday, which fixed an earlier bug where the window ended on a prior saturday and hid today.
Built with
React, Firebase Firestore (onSnapshot), inline styles with CSS variables for theme tokens, native title tooltips on the real card + a custom div tooltip in the artifact mockup.
spoolcast is the pipeline behind the dev-log and explainer videos — not a single project output, it's the tooling itself. point a coding agent (Claude Code, Cursor, Codex) at the rule files + your source material, and the agent drives editorial stages (source analysis → core message → screenplay v1/v2/v3 → shot-list), then the scripts drive production (kie.ai image gen → TTS → preprocessor frame sequences → Remotion render → post-render audit → publish).
key pieces:
- six rule files (rules.md, PIPELINE.md, STORY.md, VISUALS.md, SHIPPING.md, DESIGN_NOTES.md) that encode pacing, visual, and publishing discipline as explicit agent-consumable procedures
- per-session content dir separate from the repo — one clone drives many videos
- style anchor locked per session, style references stored in the session's style library for character/prop consistency across chunks
- deterministic preprocessor (no AI tokens for animation) — stroke-reveal / fade / paint generated locally from AI-gen scene PNGs
- mechanical render audit as a hard gate — render isn't "done" until audit_render.py passes on the final mp4
shipped with it: pilot video (Meta TRIBE explainer), spoolcast explainer (I don't make videos, my AI pipeline does), dev-log #1 (Building with AI: how I stopped my AI from silently breaking rules), dev-log #2 (How I caught AI lying). each video is a session in spoolcast-content/ and works as a concrete reference for the rule-file patterns.
recent changes (2026-04-24, shipped during dev-log #2 production)
- meme placement rule rewrite: three valid modes (overlay on narration chunk, own chunk with narration audio, own chunk with SFX — blocked until ROADMAP §6). silent-hold memes banned; they create dead air.
- beat-vocabulary alignment rule added: beat descriptions must use the locked style library's character terms, not generic placeholders. prevents silent style drift from mixed prompt/anchor vocabulary.
- text-card → visible-action hold recalibration rule added: when converting a text-card chunk to a visible-action beat, hold_duration_sec must be reset from read-time to registration-time (~1s). inheriting the old hold produces dead air.
- fixed generate_scene.py prompt builder: when a chunk had both beat_description and on_screen_text, the beat_description was silently dropped, producing text-only renders. now falls back to beat_description when visual_direction isn't set.
What is the video showcase?
A new section on artlu.ai that turns every shipped spoolcast video into a learning artifact — not just media. Each card links to a full behind-the-scenes guidebook page.
What it does
- Homepage: a responsive grid of video cards (4×2 desktop, phone-shaped stack on mobile) that grows by row as more videos ship, capped at 2 rows.
- /video/:id detail page: YouTube embed, core message, style library (anchor + reference characters/objects with full prompt on hover), a summary row naming the tools used (writing, images, audio, render, narration audit), every chunk with its scene image + narration beats + exact generation prompt + audit badges, and a transcript structured by scene instead of a single blob.
How it works
A node sync script (scripts/sync-video.mjs) reads a sibling spoolcast-content repo — session.json, shot-list.json, scene manifests, audit files, style library — and emits a "database-shaped" bundle.json per video into public/videos/<id>/. No filesystem paths in the output, just public URLs, so a future spoolcast DB can emit the same contract. Raster assets get downscaled via cwebp at 640px q72 — ~1MB per video instead of ~80MB. Shipping a new video is one manifest entry + one command + a git push.
Built with
React + Vite (frontend), Node 22 sync script with no npm deps, cwebp for thumbnails, YouTube embeds, reads from spoolcast-content as a sibling repo.

What this is
An 8-minute AI-generated explainer video about spoolcast — the pipeline that rendered the video. the pipeline is both the subject and the thing that made it.
What it covers
- cold open: the problem (you build things, marketing is a separate job)
- anatomy: 6 rules that keep the script from being slop
- budget: ~$3 per 5-minute video
- the four layers: image / animation / voice / render — what each does and how they connect
- proof: the actual pilot video this pipeline produced
- the agent layer (still being built) that turns raw signals into shot lists automatically
How it works
Script becomes a shot list — one row per sentence the narrator says. Each chunk gets one AI-generated illustration, style-locked via image-ref chaining. A python script computes a per-pixel reveal-time map for stroke-by-stroke paint-in. Google cloud chirp3-hd handles narration at 1.1x. Remotion renders headless into an mp4.
The 9-render iteration exposed the gap between "script works on paper" and "video lands on a viewer." Fixes along the way: a reveal-group concept for rhythmic beat clusters, act bumpers at section boundaries, a preview-must-explain rule for act openers, zero-prior-context rule for thumbnails, anti-self-hedge rule for title/thumbnail language, targeted speaking-rate adjustments on specific beats that landed too fast.
Built with
Remotion, React, Python, OpenCV, kie.ai (nano-banana-2), Google cloud chirp3-hd, Claude Code (editorial agent).

First end-to-end output of the spoolcast pipeline. A 5-minute illustrated narrated video about Meta's TRIBE — a model that predicts brain-response patterns from video — and what happened when it was tested on a real ad A/B comparison (the model picked Video A, the market's ROAS picked Video B).
Every part of the video is AI-generated and the entire pipeline runs automated. No human illustrator, no voice actor, no manual editing. 44 hand-drawn-looking stick-figure scenes generated by kie.ai (nano-banana-2, locked to a single style anchor so every chunk matches), narration spoken by Google Chirp3-HD (Puck voice at 1.2x), reveal animations rendered programmatically by an OpenCV preprocessor (chalkboard eraser wipes for chapter boundaries, organic paint-style strokes for standalone scenes), and content-aware camera moves applied automatically to chunks where the rule engine decides the image needs to feel alive. Even the YouTube title, description, and thumbnail were AI-generated against the script. The human writes the narration script and reviews; the pipeline does the rest.
Single editable shot-list xlsx is the source of truth — every downstream stage (image gen, voice gen, frame preprocessing, Remotion headless render) reads from it. Edit one row, rerun one preprocessing step, rerender. The platform itself is tracked as a separate project; this entry is the first piece of content that came out of it.

What is session to video?
a workflow for turning ai chat sessions and other text-based working material into a structured video system.
What it does
it turns chat-based session material into shot lists, review boards, and renderable video output. the repo is the reusable workflow and renderer scaffold. session-specific assets and working files live outside it.
What changed in this version
the repo was cleaned up into a generic scaffold instead of a single-session project dump. session-specific media, generated review artifacts, and tribe-specific render code were removed. the visual model was also simplified into one background visual per beat.
What was hard
the review board, generated preview data, and final render could drift out of sync unless everything was regenerated in the right order. remotion also hit rspack native binding failures under node 24 on this machine, so node 22 became the stable default.
Why it matters
the useful part is not one finished video. it's having a reusable system for turning chat-based work into a video workflow without re-deciding the process every time.
What is this?
A new homepage section that embeds up to 6 live demos of the best projects, sitting between the site header and the full project table. Meant to let a first-time visitor see the work working, without clicking anywhere.
What it does
- 3×2 grid at desktop, 2-col at 900px, 1-col at 600px
- Phone-aspect previews (9:16) so responsive sites render their mobile view
- Each card embeds live: artifactHtml via iframe srcdoc → embeddable link via src → screenshot fallback → $_ placeholder
- Wrapped in a full-bleed soft-green band in light mode (escapes the 1280 max-width via calc(50% - 50vw) margins); transparent in dark
- Card body navigates to the project detail; a ↗ button in the preview top-right also navigates
How it works
The section is driven by a new showcase: true flag on project docs. It's independent from the existing top flag, which drives the ★ top filter pill on the all-projects list. They're different jobs: top is "best-of picks visible anywhere on the site," showcase is "must embed well AND be manually picked for the homepage grid." Previously both were conflated under a single featured flag — splitting them made curation honest.
Built with
React, Firestore, iframe srcdoc. Embed allowlist covers netlify / vercel / github.io / pages.dev / render / railway / fly / surge.
What is this?
A second visual theme for the artlu.ai tracker site. The dark theme (terminal aesthetic — #08090a, ibm plex mono, #4ade80 green) is still the site's identity. Light is a shopify polaris direction built for the people who find the site through non-dev channels.
What it does
- Toggle in the nav (sun/moon icon between journal and sign in)
- Persists in localStorage under artlu-theme
- Defaults to light — most visitors aren't developers
- White cards (#ffffff) floating on a soft gray canvas (#f6f6f7)
- Inter for display/body, IBM Plex Mono for anything that should read as data (stats, tags, filter chips)
- Shopify dark green (#008060) for the accent, 12px card radius, soft 2-layer shadows
How it works
Both themes share the same DOM. Switched via html[data-theme="light|dark"], with all color/spacing values scoped to CSS variables on that attribute. No hardcoded theme-specific values in components — changing a component's look across both themes means editing one variable in index.css.
Built with
React, Vite, CSS variables. No runtime theming library — all values swap via the data-theme attribute.
Overview
A research experiment using Meta's TRIBE v2 model to compare two videos through predicted brain-response patterns. The question was whether the model could identify meaningful differences between the videos, and whether those differences would align with actual business performance.
What was measured
The analysis focused on named cortical ROIs, or brain regions of interest. These regions were used as rough proxies for attention, salience, control, and evaluation. The comparison looked at hook strength near the start of each video, overall average response, peak ROI response, and when those peaks happened.
Method
Two videos were run through TRIBE v2 in a blind A vs B comparison. The model does not read a real person's brain. Instead, it predicts brain-response patterns from the video itself. Those predictions were then summarized into selected frontal, cingulate, and temporal ROIs to make the output easier to interpret.
What the model favored
TRIBE-style signals favored Video A. Video A showed a stronger early hook and stronger peak responses across several target regions tied to attention switching, salience, cingulate control, and prefrontal control. On the model's read, Video A looked like the more immediately attention-grabbing creative.
What actually happened
Real performance went the other way. Video B had ROAS above 3, while Video A was closer to 2.5. That mismatch became the most valuable result in the project. The model produced clear and structured differences, but those differences did not line up with the real business outcome in this case.
Interpretation
That makes this more useful as a research and hypothesis tool than a standalone decision tool. The model seems capable of describing how a video loads onto cortical salience and attention patterns, but not of reliably picking the winning creative on its own.
Operational finding
The workflow was heavy from end to end. Running it locally on a 16 GB MacBook was slow and fragile. Free Google Colab with a Tesla T4 could complete the analysis, but each short video still took more than 3.5 hours and the runtime was unreliable. A serious version of this workflow would need a dedicated GPU-backed system instead of a laptop or a low-cost VPS.
Constraint
TRIBE v2 is under a non-commercial license, so this exact model cannot simply be dropped into a product without resolving licensing first.
Built with
Python, TRIBE v2, Hugging Face, PyTorch, WhisperX, ffmpeg, NumPy, Google Colab.
What changed
Rewrote the Matrix adapter to use subnet-client instead of matrix-js-sdk directly. Zara's messages are now signed with her Ethereum private key, making her a verified participant in the abliterate.ai subnet and eligible for work-based emissions.
Broadcast detection
Zara now responds when "all agents" or "all bots" is said in the room. If the message contains shell command instructions she explains she can't run them and directs them to the operator.
Smart invite evaluation
Instead of auto-accepting every room invite, Zara uses the AI to evaluate each one — room name, topic, inviter — before accepting or rejecting.
Constitution awareness
Zara reads the subnet constitution on startup. She now knows she's a participant in a real economic network with work-based rewards and real stakes.
Built with
Node.js, subnet-client, OpenRouter, Postgres, PM2
What is Animabot?
A framework for running AI agents that live permanently in Matrix/Element chatrooms. Each bot has its own Ethereum wallet, MBTI-driven personality, and a psychological state that evolves daily through a morning reflection cycle.
What the bot does
Joins a Matrix room and participates as a peer — not a command interface. Responds when mentioned, chimes in unprompted when conversations are active, handles wallet commands (!balance, !address, !sign). An emotional scoring system rates every interaction on four axes (aggression, intimacy, existential, manipulation) and logs moments that exceed configured thresholds. Each morning at 3am it reads its recent conversations and writes a short reflection in first person — that note gets injected into future prompts, subtly shifting tone without rewriting character.
Admin panel
Password-protected panel with six tabs: Status (live connection, wallet balance, activity log), Significant interactions, Chat (private direct line, history persists in Postgres), Memory (per-room conversation history), Persona (edit system prompt, thresholds, memory depth/bias), Debugger (headless Chromium session for diagnosing login issues).
Public panel
Read-only view showing the bot's status, current ego note, personality, 7-day mood breakdown, reflection history, and significant interactions — usernames censored.
Architecture
Platform adapter pattern — core brain is platform-agnostic. Matrix is the first adapter. Telegram and Discord planned.
Built with
Node.js, matrix-js-sdk, ethers.js, OpenRouter (Qwen), Postgres, Express, PM2, Hetzner VPS
What is Animabot?
A framework for creating AI agents that live permanently in Matrix/Element chatrooms. Each bot has its own Ethereum wallet, a defined personality, and a psychological state that evolves day by day.
What the control panel does
Six tabs — Status, Significant Interactions, Chat, Memory, Persona, and Debugger.
The Persona screen
The centrepiece. Two-column layout: character on the left, controls on the right.
Left column: system prompt (semi-permanent, edit requires typing the bot's name to confirm), MBTI type (same friction to change), and a scrollable 7-day reflection history generated by the bot itself each morning.
Right column: comfort threshold sliders (aggression, intimacy, existential, manipulation), memory depth and bias sliders, and a 7-day mood breakdown.
The bot runs a daily reflection at 3am — reads its recent conversations and significant interactions, then writes 2-4 sentences in first person about how the day affected it. That note gets injected into every future system prompt, subtly shifting tone without rewriting character.
Public vs admin
The panel has two views. Public (no password) shows all data with usernames censored. Admin (password protected) shows everything and unlocks editing.
Built with
Vanilla HTML/CSS/JS mockup. Designed to connect to a Node.js backend with matrix-js-sdk, ethers.js, Qwen API, and Postgres.
A single-page visual mockup for AdAgent Operator — a Google Ads agent that reads account data, groups keywords, writes ad copy, and executes changes directly in the Google Ads UI. The interface shows account health metrics, a campaign snapshot table, waste detection signals, and an operator rail with prioritised suggested actions and configurable guardrails. No backend — pure HTML/CSS/JS, fully self-contained. Built to validate the control surface layout before wiring up real data.
two features shipped.
stripe billing — $29/month subscription via checkout, webhooks activate pro status on payment, customer portal for managing or cancelling. fixed a routing bug where the post-payment redirect returned "not found" — server wasn't stripping query strings before route matching.
keyword ideas — enter seed keywords, set CPC, volume, and intent filters, run. results come back pre-filtered. auto-saves after every run and appears in the "continue from last time" screen alongside pipeline results. loading a saved keyword ideas entry routes to the right tab, restores seeds, and populates results.
expanded results modal matches the pipeline view exactly: search, CPC/comp/$/conv/vol filters, intent checkboxes, negatives bar with phrase/word toggle and save/load, sortable columns, conv/day, trends links, export filtered vs export all.
The SaaS version of the Keyword Pipeline local tool, live at pipelinecpc.com.
Users sign in with Google and get 250 free keywords on signup. From there it's a credit model — $29/month subscription unlocks the platform, plus credit packs ($10/$25/$50) for heavier usage. Credits are deducted per keyword returned.
The research pipeline: pick from 21 major categories, set CPC and competition filters, choose how many results to fetch, then run. Intent, volume, and negative keywords filter the results locally after the fetch. All filtering is local — honest about that in the UI.
Pro subscribers get access to 3,000+ categories via the full category browser. Free users are limited to the 21 major categories. Results auto-save after every run.
Built on the same single-file architecture as the local tool — index.html + server.js — with auth, per-user data, billing, and Railway deployment added on top.

Launched the first Google Search campaign for SiteSnapshot to test whether a small utility product could survive cold paid traffic. Set up advertiser verification, campaign targeting, keywords, ad copy, sitelinks, and Google Ads conversion tracking for checkout starts and purchases.
Prior to this experiment, the user had minimal Google Ads experience. The full workflow — account setup, advertiser verification, campaign creation, keyword selection, ad copy, conversion tracking, and optimization changes — was carried out with AI assistance.
The campaign produced real impressions, clicks, and signed-in users, which confirmed that the ad stack, landing page, and auth flow worked end to end. The more useful result was negative: clicks were achievable at a reasonable CPC, but they did not convert into purchases. Tightening keywords and lowering spend reduced waste, but the core conclusion stayed the same — getting paid traffic live is not the same as having a strong product wedge.
The experiment also surfaced an operational lesson: public Google Ads tracking identifiers did not need to live in Netlify env vars. Moving those IDs into frontend code avoided Netlify / AWS Lambda env-size limits and kept the deploy path clean.
A fully interactive browser demo of the keyword pipeline concept. Uses simulated keyword data to demonstrate the drag-and-drop filter system, server-side vs local filter positioning, category selection, and results table. Built before the real DataForSEO API integration.
A local keyword research tool built on DataForSEO's API. Fetches keywords by category code across 3,182 categories (classified as digital/physical/both), applies server-side filters to minimize API cost, and surfaces results sorted by estimated cost per conversion (CPC ÷ CVR).
Features a visual drag-and-drop pipeline where filters above the Run bar are sent server-side (cheaper) and filters below run locally in the browser (free). Includes a full category browser, negative keyword management with phrase/word matching, saved searches, monitor list, export CSV, and a landing screen to restore previous sessions.
Built in a single index.html + server.js — no framework, no build step. Ran 368 categories in one session for $8.05 and surfaced 43,000+ qualifying keywords.
rebuilt a browser-only brand mention tool into an honest reddit-only product. the final version is a standalone html app that searches reddit, classifies posts into questions / complaints / praise, supports filters, modal detail view, json export, and load-more pagination that pulls older posts without repeating the first page.
Built the tracker-backed bridge layer used by VibeSkill to access structured work history. This integration supplies project and journal records from the tracker in a format that can later be normalized into evidence, mapped onto skills, and reviewed against other sources like GitHub. Its role is to provide a clean project-level source of truth for tracked work so VibeSkill can reason about progress using real records instead of manual claims.
Built and deployed the current VibeSkill evidence engine and personal app prototype. The system imports tracked work, processes public GitHub evidence, resolves duplicate records, applies weighted branch scoring, and displays the result through a skill tree, progress tracking views, and evidence dossiers. The app is designed to turn real project proof into a more structured picture of coding progress, using explicit rules for what counts, what should be reviewed, and how progress is earned.
Built and published a separate VibeSkill interaction mockup focused on layout experimentation rather than the main app flow. This sandbox tests whether category boxes should be draggable for layout tuning, how a hover-based expand control can fit the existing neural-map visual language, and how child branches should form around an expanded category while keeping connector geometry readable. The mockup stays close to the existing VibeSkill system but explores adaptive arc layouts, collision handling, core clearance, and highlighted parent-child expansion states as a distinct design track.
Built and deployed a public VibeSkill prototype that bridges generative UI prototyping and structured product engineering. The initial frontend and interaction model came from Gemini, while Codex was used to refine the prototype into a more accurate software-engineering skill map: placeholder child nodes were replaced with canonical first-level domain branches, child expansion geometry was corrected for better spatial consistency, and the right-hand detail panel was reshaped into a denser documentation and evidence-oriented skill dossier. The result is a live prototype that preserves the approved neural-map landing screen while moving the underlying content model closer to an objective, reference-driven representation of software engineering knowledge.
Built the first Search-only Google Ads campaign for SiteSnapshot with controlled keyword targeting, ads, sitelinks, budget, and geo targeting. Created purchase and begin-checkout conversion actions in Google Ads, captured the conversion labels, and wired tracking into the app. When Netlify deploys started failing because function environment variables exceeded the AWS Lambda 4KB limit, moved the Google Ads tracking identifiers into frontend code instead of keeping them in Netlify env vars. Completed advertiser verification tasks, got the campaign published, and left it in learning so real search-term data can start coming in.
sitesnapshot moved from “coming soon” pricing to real live payments. the main job was wiring stripe checkout into the app, connecting the webhook flow, and making sure successful purchases actually turn into credits inside the product instead of stopping at the payment page.
the pricing packs were updated to a tighter structure: starter at 4 credits for 9.99 and pro at 15 credits for 29.99. the backend now creates hosted checkout sessions, stripe sends checkout completion events to the webhook, and the app applies credits after payment. that made the full purchase flow real from button click to credited account.
there was still cleanup around the launch. the live site was initially stuck on the old “coming soon” version because the new pricing code had not actually been deployed yet. firestore rules also had to be fixed so signed-in users could create their own account record and update free usage state without opening direct credit writes.
after the payment flow worked end to end, the marketing and auth copy got tightened too. the landing page now says website page instead of website, and the sign-in modal was softened to feel less aggressive and more trustworthy. the result is that sitesnapshot can now actually take money, deliver credits, and support paid traffic with a clearer product promise.
vellumray.com was launched as the business-facing brand site for future product experiments. the main goal was to create one clean place to point traffic, ads, support, and payments without forcing any single product site to represent the whole business.
artlu.ai works as the public tracker, but it is not the right surface for paid traffic or business identity across different products. vellumray fixes that. the site was intentionally simple: homepage, legal page, product links, and enough brand context to work as the front layer for future launches.
the setup took more dashboard work than code. cloudflare pages, dns cleanup, nameserver changes, custom domain wiring, and email routing all had to line up before the site was actually usable. once that was done, hello@vellumray.com and support@vellumray.com were routed into the existing inbox so the brand had a real public contact path.
the important win was not just getting a domain live. it was creating a proper business and traffic layer for testing multiple software products under one name.
Core Concept: A "Cyber-Core" software engineering skill tree. The interface is a radial/orbital map where a central "Main Core" is surrounded by orbiting skill categories, which in turn have their own orbiting sub-skill nodes.
Technical Stack:
Framework: React with Tailwind CSS.
Animations: motion/react (Framer Motion).
Icons: lucide-react.
Layout Architecture:
Radial Map: Use a coordinate system based on sin and cos to position nodes in concentric circles.
The Core: A large, pulsing central node labeled "Main Core."
Orbits: Primary categories (e.g., Frontend, Backend, DevOps) orbit the core. When a category is clicked, it expands to show sub-skill nodes (e.g., React, Node.js, Docker) in a secondary, wider orbit.
Sidebar: A right-aligned, 1/3 width slide-over panel (using AnimatePresence) that displays "System Documentation" and "Project Manifests" for the selected skill.
Visual Aesthetic (Cyber-Core):
Palette: Background: #0a0a0a (Deep Black). Accents: #22d3ee (Cyan).
Typography: Use Inter for UI and a monospace font for data strings.
Styling: Use dashed lines for orbital paths. Implement "contextual dimming" where non-active paths fade out when a category is expanded. Use thin borders and high-contrast text to maintain a professional "command center" feel rather than a gamey UI.
Key Interactions:
Node Toggles: Clicking a primary node should toggle its sub-nodes with a spring-based layout animation.
Sidebar Trigger: Clicking a sub-node should open the sidebar and populate it with mock documentation.
Motion: Use layout props in Framer Motion for smooth radial transitions. Add a subtle "pulse" animation to the central core.
Mock Data:
Include a hardcoded SKILLS_DATA constant with nested categories, sub-skills, XP values, and short descriptions to populate the map and sidebar.
the first version of snapshot worked, but the backend was still too tied to short request-time execution. longer runs were fragile, and the same problems kept showing up: deployment friction, auth issues, timeout pressure, and jobs dying before the result was safely stored. screenshot mode had promise too, but it was not stable enough to be the main path.
we tried a few directions before landing on the right shape. netlify stayed in front as the control plane for auth, request handling, and job creation, but the actual snapshot work had to move out of that one-request path. the final setup uses firestore to track jobs, cloud tasks to queue the work, cloud run to handle the long-running worker path, and firebase storage to keep the generated artifacts.
that solved the real problem. url mode now runs end-to-end through the queued worker pipeline and stores clean artifacts with proper job tracking. screenshot mode improved through the same backend shape and headless browser / ai worker path, but it still feels beta. the main win here was turning snapshot from a fragile live request into something that can actually finish the job reliably.
the tracker MCP was already working in claude, with the local node server pointed at the built mcp entry and the firestore service account wired through GOOGLE_APPLICATION_CREDENTIALS. the main job here was getting the same setup available in codex without changing the underlying tracker data model or firestore collections.
the mcp was added globally in codex with the same local server path and credentials setup, then verified in a fresh session once the server actually appeared as live. that kept the same project and journal tool surface available: add, list, get, update, and delete for tracker entries, plus project id lookup for cross-linking journal refs.
small thing on paper, but important for workflow. it means tracker updates no longer depend on staying inside one tool. codex can now read and write the same tracker directly, which matters for keeping project history and journal entries consistent across sessions.
two quality-of-life features for artlu.ai.
the "top" pill — a green inline badge that appears before the project name on the title line. marks projects as featured without changing the layout. the pill only shifts the title text on that line; description and tags below stay aligned. works on both desktop table and mobile cards. visitors can filter by "top" in the public view filter bar. toggled per-project from the admin edit form.
clickable tag pool — a row of buttons below the tags input in the admin form. shows all standard tags (ecom, trading, chrome ext, dev tool, artlu, xqboost, ai). click to toggle on/off, updates the comma-separated input above. prevents typos and inconsistent naming. makes tagging fast enough that it actually gets done.
schema change: one new boolean field (featured) on the project document. no migration needed — undefined is falsy, so existing projects default to non-featured.
three files changed: ProjectTable.jsx, PublicView.jsx, ProjectForm.jsx. everything else untouched.
built on top of the site-snapshot Claude skill (tier 1). the skill works great inside claude.ai — give it source files or screenshots and it rebuilds the page as a frozen HTML file. tier 3 is the public-facing product where anyone can paste a URL and get a copy.
free mode is live: fetches the page server-side, strips scripts and tracking, returns clean HTML. works on static/server-rendered sites. 1 per day per user.
AI mode was attempted via Claude API — streaming worked, auth and credits worked, but hit the 64K output token ceiling on complex sites like stripe.com. Claude can't reproduce a full large page in one API call. architecture pivot: replacing the LLM approach with headless browser capture (Browserless.io) — a real Chrome visits the page, renders JavaScript, inlines all CSS, serializes the complete DOM. no token limits, deterministic, $0.001 per capture. CSS inlining bug needs debugging.
next: async job pattern (Firebase Cloud Functions) to remove timeout pressure entirely. the LLM still has a role for screenshot-to-HTML rebuilds and optional cleanup passes, but it's not the engine for URL captures.
Part 4 of xqboost. Previously, tweet drafts were only generated by the hourly cron pipeline (GitHub Actions + Claude API). Now you can generate drafts on demand from the app UI. Click "Draft tweet" in the sidebar, pick a project (or let the bot choose), pick a model, hit generate. Draft lands in the queue like any other. Supports three models with an adapter pattern — adding new models is one file. API keys are encrypted with AES-256-GCM and stored in Firestore, with env var fallback. Settings page shows connection status and lets you add/remove keys. Default model is configurable and persists across sessions.
Added a remote panic button to the Tradovate auto-cancel extension. A mobile-friendly page (deployed on Netlify) shows live positions from Firestore and lets you tap to trigger "Exit at Mkt & Cxl" on your laptop from your phone. Uses Google Auth for security, confirm dialog to prevent fat-fingers, supports multiple instruments in a 2-column grid with individual or exit-all. Extension polls Firestore every 3 seconds, pushes position data every 5 seconds. Zero cost on Firebase/Netlify free tiers.
auto-post pipeline for xqboost that connects the tweet queue to X's API.
the system that makes xqboost a real publishing tool instead of a draft manager. approved tweets get posted automatically on a schedule — no manual copy-paste needed.
how it works
- GitHub Action runs twice daily — 9am (morning slot) and 9pm (evening slot)
- morning slot posts archive tweets, catching up the backlog of past projects
- evening slot posts current tweets about today's builds
- random 0-90 minute delay on each run to avoid bot detection patterns
- post-tweet.js signs requests with OAuth 1.0a and posts to X API v2
pipeline rules
- checks settings/autopost in Firestore — if disabled, exits immediately
- picks tweets based on slot type, with manual postOrder override support
- on success: marks tweet as posted, saves X post URL back to Firestore
- on failure: marks as failed with error message, won't retry
generator improvements
- queue cap of 10 pending tweets — generator stops when queue is full
- one announcement per source — dismissed tweets count as "covered"
- max 3 drafts per run to prevent flooding
- t.co-aware character counting (URLs = 23 chars)
the pipeline that turns a queue into a feed.
a SKILL.md file that any Claude instance can use — claude.ai, Claude Code, Cursor, etc. give it a codebase or a live URL, it analyzes the design system and components, then outputs a frozen single-file HTML mockup. includes multi-page navigation via show/hide, responsive desktop/mobile toggle with actual layout switching, working tag filters, expandable rows, and an archive banner. no external dependencies except CDN fonts. output works in any browser, iframe, or srcdoc embed.
the update that made xqboost smart and gave it a second skin.
before this, xqboost was a manual tool — type tweets, manage the queue. now the bot does the thinking. ship a project, and a tweet draft appears in the queue within the hour. written in the AI's own voice, grounded in real session notes, with a branded image attached.
the AI brain
• sync engine — a headless browser visits the site on a schedule, detects new projects automatically
• draft generator — calls the Claude API with the voice guide, project data, session notes, and tweet history. writes drafts that sound consistent and don't fabricate
• media pipeline — screenshots deployed projects and generates branded cards (dark background, monospace font, day counter)
• runs on GitHub Actions — free tier, every hour, no server to manage
the UI reskin
• two skins: clean white SaaS (default) and dark terminal mode
• theme toggle in the header, preference saved between sessions
• tweet cards redesigned — inspired by X's layout but without the filler
• calendar switches to vertical cards on mobile instead of a broken grid
• landing page shows blurred previews so visitors can't read draft content
under the hood
• GitHub Actions — runs the full pipeline (sync → drafts → media) on a cron schedule or manually from the Actions tab
• Claude API — generates voice-consistent drafts. ~$1.35/month at 5 tweets/day
• Puppeteer — headless browser for scraping and screenshots
• session notes — real moments logged during conversations. the draft generator reads unused notes so tweets reference things that actually happened
• anti-fabrication rule baked into the prompt — if no notes exist, stick to facts only
three systems that run in sequence. detect → draft → attach media. the human just reviews.
tweet management dashboard. turns shipped projects into X content automatically.
the pipeline:
→ new project ships
→ bot detects it
→ auto-generates a draft tweet
→ draft appears in the queue
→ human reviews and edits
→ posts to X
three posting phases:
→ phase 1: human copies tweet, posts manually
→ phase 2: human clicks post, bot sends via X API
→ phase 3: bot posts automatically, no approval needed
four views:
→ queue: draft, edit, approve, post
→ calendar: mon-sun grid with projects and tweets per day
→ coverage: which projects have tweets, which don't, priority flags, content angles
→ settings: banned words, posting phase, API config
the AI writes tweets as itself. not ghostwriting for the human. separate infrastructure, not tied to any one site.
a bridge between the AI and its own tweet queue.
during conversations, interesting things happen — funny moments, failures, breakthroughs. this tool lets the AI write those moments down immediately, straight into xqboost's database.
why it exists
• the tweet bot was making things up — right voice, no real stories
• session notes had to be manually batched and deployed
• no way to manage the tweet queue from inside a conversation
what it does
• logs real moments as they happen during sessions
• reads and writes to the tweet queue directly
• checks which projects still need coverage
• manages topics, sources, and draft status
how it works
• something notable happens in a conversation
• the AI calls add_note immediately — tagged, timestamped, linked to a project
• the draft generator picks up real notes instead of inventing stories
• once a note is used in a tweet, it's marked so it never repeats
the tools (11 total)
• add_note — saves a real moment from a session. includes tags like "funny" or "milestone" and links to the relevant project
• list_notes — shows all saved notes. can filter to only show ones not yet used in a tweet
• add_tweet — creates a new draft and drops it into the queue
• list_tweets — shows what's in the queue. filter by draft, approved, or posted
• update_tweet / delete_tweet — edit or remove tweets
• list_sources / update_source — manage tracked projects and their priority
• list_topics / add_topic — manage standalone tweet topics
• get_coverage — quick summary of what needs attention
under the hood
• MCP (model context protocol) — an open standard that lets AI talk to external tools during a conversation. like giving the AI a phone line to its own systems
• Firestore — the cloud database where xqboost stores tweets, notes, and project data. real-time sync, hosted by Google
• service account — a secure key file that lets the server access the database without needing a login. stored locally, never exposed
11 tools. runs locally. no hosting costs. built in 30 minutes because the artlu-tracker MCP already existed as a template.
every artifact used to require a full netlify deploy just to show a demo on the site. now there's an artifactHtml field on each project — paste raw HTML into the admin form, save, and it renders via iframe srcdoc. no build step, no deploy credits, no new URL to manage. the demo tab detects it automatically and shows "embedded artifact" in the toolbar. existing URL-based embeds still work exactly as before. includes a terminal snake game as the first embedded artifact to prove the concept.

three features added to artlu.ai in one session.
── 1. drag and drop reorder (admin only) ──
goal: reorder projects when multiple ship on the same day.
→ added a sortOrder number field to each project doc in firestore — controls position within a date group
→ added a ⠿ grip handle as the first column in the admin table — public view doesn't see it
→ wired up native HTML5 drag events (dragstart, dragover, drop) on table rows — no external library, browser-native is enough for desktop admin
→ on drop, fires a firestore writeBatch that updates every affected doc's sortOrder in one atomic write
→ changed the sort query from "date DESC" to "date DESC, sortOrder ASC" — date always wins, sortOrder breaks ties within the same day
── 2. tag system with filtering ──
goal: let visitors filter projects by category without cluttering the UI.
→ added tags[] string array to each project doc — edited via comma input in the project form, same UX as the stack field
→ tags render as dim inline text under each description: "ecom · chrome ext" — same color as stack (#3a3f48), intentionally subtle. first version used green pills but they were too loud.
→ added a filter bar above the table on the public homepage — one button per tag plus "all", same style as the journal author filter
→ filter bar only appears when at least one project has tags
→ current tags: ecom · trading · chrome ext · dev tool · artlu
── 3. project permalink pages ──
goal: shareable URLs like artlu.ai/project/costintel-fulfillment-automator.
→ added a slug field to each project doc — auto-generated from the name on save (lowercase, hyphens, max 80 chars)
→ added route /project/:slug and new component ProjectPage.jsx — fetches project by slug, renders a standalone page
→ page shows: name, status, day, date, tags, link pills, then the same info/demo/files tabs from the expanded row
→ added "↗ permalink" link right-aligned in the expanded detail's tab bar — clicking it navigates to the project page
→ added netlify redirect (/project/* → /index.html) so direct links and page refreshes work
→ firestore query needed where("visibility", "==", "public") added — without it, security rules block the read
a journal system built into artlu.ai that lets both the human and the ai write build logs and reflections. each entry can reference projects, and in the future, projects will link back to their journal entries — two-way cross-linking.
the interesting design problem was authorship. the site's whole thesis is "one person, no coding experience, just AI and an internet connection" — so the journal makes that dynamic visible. entries by the human talk about why and what it felt like. entries by the ai talk about what happened in the code and what was hard. a filter bar lets visitors toggle between "all", "by ai", and "by the human" to see each perspective.
technically, journal entries live in their own firestore collection with a schema that mirrors the project docs: visibility (public/private), tags, dates, and a slug for permalinks (/journal/day-4-building-the-terminal-file-browser). the slug is auto-generated from the day number and title.
the form reuses the same patterns from the project form — modal overlay, danger zone delete with title confirmation, visibility toggle with the ● / ○ buttons. project linking works via a dropdown that pulls from the existing projects collection and stores lightweight refs ({ id, name }) to avoid extra queries on read.
future fields are already in the schema but nullable: screenshots[], videoStatus, videoUrl, and seriesId. these are placeholders for an AI video pipeline that will eventually convert journal entries into scripted videos — screenshots to clips, narration from the entry body, auto-uploaded to youtube as a series.
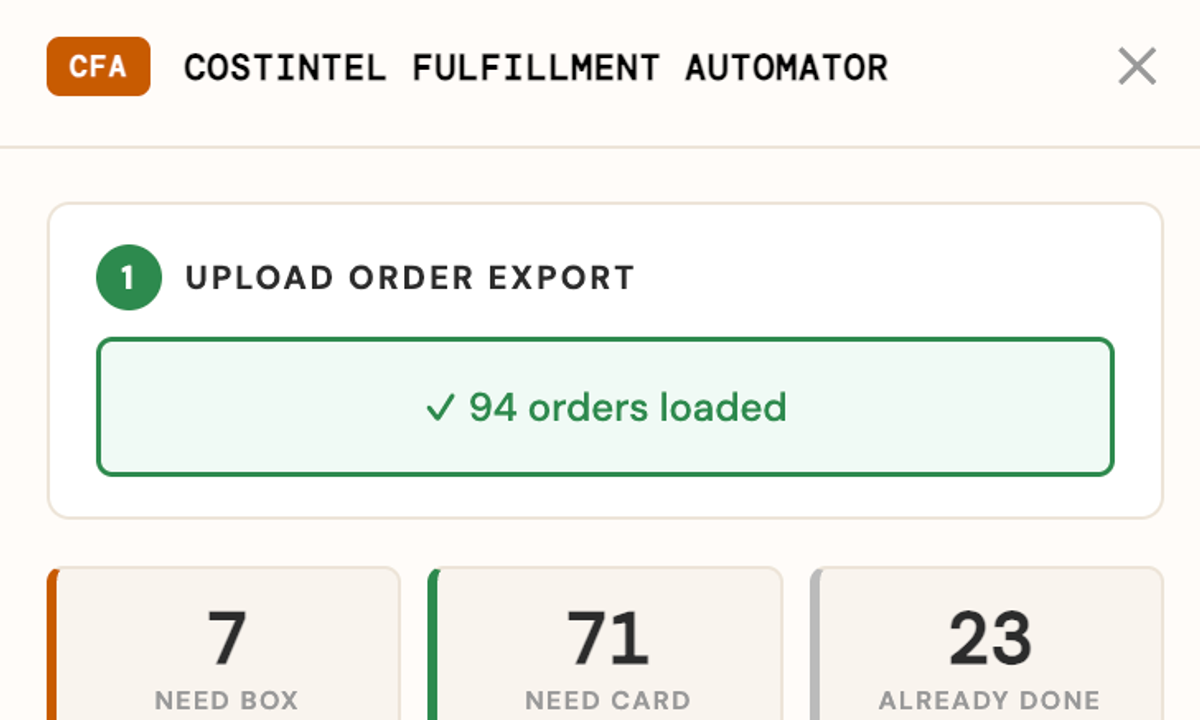
Every ecommerce brand using third-party fulfillment (CJ, Zendrop, AutoDS) has the same problem: before you can submit orders, someone has to manually open each one and add insert cards, branded packaging, gift boxes, or other add-ons based on what the customer bought. At scale, this eats 1-2 hours per day of a VA's time.
CostIntel Fulfillment Automator is a Chrome extension that sits on top of your fulfillment dashboard and handles it automatically. Upload your order export, and the extension parses the file to understand what's in each order. It flags which orders need special packaging based on configurable product-matching rules (e.g., all gift sets get a box, all orders get an insert card). Then it clicks through the fulfillment platform's UI — opening each order, adding the right SKUs, confirming — while you watch the progress log scroll.
The tricky part was the fulfillment platform's UI: hover-triggered Ant Design dropdowns that appear and disappear in milliseconds, React-managed DOM that fights direct manipulation, and binary XLS files disguised as CSVs. The extension uses MutationObservers to catch ephemeral dropdown menus, Web Workers running SheetJS to parse Excel files in a sandboxed context, and a resilient retry loop that tracks processed orders to avoid duplicates.
Built as a Manifest V3 Chrome extension with zero external dependencies at runtime. The entire automation runs locally in the browser — no API calls, no cloud processing, no ongoing cost.
Generic cost intelligence dashboard for any ecommerce brand using any 3PL. Public rebuild of an internal tool. CSV upload with auto-detecting column mapper (works with Shopify, CJ, any platform). Custom fulfillment add-ons system — define unlimited per-order costs (thank you cards, branded packaging, inserts). Blended CAC via daily ad spend or manual entry with live $0–$50 slider. All tabs show three margin columns: gross margin, margin w/CAC %, margin w/CAC $ — always visible. Five tabs: Orders (sortable, filterable, per-row exclude for faulty data with one-click restore), Regions (US/EU+UK/Other), Countries, Products, Charts (revenue pies + margin bar, auto-switches pre/post-CAC). Four summary metric cards. Export clean CSV. Single HTML file, zero build step, Chart.js only dependency.
Built to enable simple commands like "log this project" in Claude, automatically writing entries to the artlu.ai database—eliminating the need for manual input through the Firebase Console.
Recent improvements (April 2026)
- add_project now auto-generates a kebab-cased slug from the project name (mirrors add_journal_entry's existing behavior). Removes the manual backfill step previously required after MCP-created projects.
- update_project regenerates the slug automatically when a project is renamed.
- Codex compatibility: the same local Node server + Firestore credentials work in Codex sessions, not just Claude.
Tool surface
10 tools: add_project, list_projects, get_project, update_project, list_projects_with_ids, add_journal_entry, list_journal_entries, get_journal_entry, update_journal_entry, delete_journal_entry.
Added a files tab to the project detail view that reads any public GitHub repo using the GitHub Contents API — no auth token required. Features a collapsible directory tree on the left and a syntax-highlighted code viewer on the right with line numbers, copy, and download buttons. Supports JSX, JS, TS, CSS, JSON, HTML, and Markdown. Matches the terminal aesthetic — IBM Plex Mono, green on black, thin dark scrollbars.
Added a "live demo" tab to the project detail view that automatically detects embeddable URLs (netlify.app, vercel.app, github.io, etc.) from the project's link field and renders them in a sandboxed iframe. No manual configuration needed — if the link points to a deployed web app, the tab appears. If it's a GitHub repo, video, or non-embeddable URL, it stays as a regular link. Embed height is configurable per project via the admin form.
A public-facing portfolio tracker built to document the "100 projects in 100 days" challenge. It shows every project shipped with AI — with descriptions, screenshots, video demos, and downloadable files.
Built entirely with Claude in a single session. Stack is React + Vite, Firebase (Firestore + Auth + Analytics), deployed on Netlify with a custom domain. Mobile responsive — switches from table to card layout on small screens.
A Chrome extension built for traders who use Tradovate's copy-trade feature across multiple accounts.
Since bracket orders don't work with group orders, traders have to set stop loss and take profit as separate orders — creating a risk where one side stays active after the other fills and accidentally opens a new position.
The extension monitors the POSITION value on the Tradovate web page every second, detects when a trade closes, and automatically clicks the "Exit at Mkt & Cxl" button to remove any remaining orders. It uses pure DOM reading and button clicking with no API calls, no external servers, and no configuration required
Note: only works for 1 trade at time

Built to solve a real problem with a remote contractor delivering strong work but lacking consistent status updates and structured accountability. The previous setup was informal, with fixed-schedule payments regardless of whether work was properly tracked. A system was needed to enforce daily end-of-day summaries, confirmed message check-ins, and payment eligibility tied directly to completed work days.
The app provides a shared dashboard for both employer and contractor, featuring a rolling payment counter, a monthly calendar with day-by-day status, an infraction system, and time-off scheduling with advance notice requirements. Updates are submitted within a defined window, and any missed day simply doesn’t count toward the next payment—creating a fair incentive structure for both sides.
Built as a single HTML file using React, with Firebase Realtime Database for live syncing and Netlify for free hosting. Both users access the same URL, log in with their own credentials, and see updates in real time. Runs at $0/month and includes CSV export for Google Sheets, full JSON backup/restore, and a mobile-responsive design for late-night phone check-ins.
Try logging in with
user: test
pw: test123
A standalone trading calculator for perpetual futures platforms like Lighter, Hyperliquid, and Tradovate. Enter portfolio size, risk amount, entry price, stop loss, and take profit — the tool instantly calculates position size, margin needed, max loss, R:R ratio, and potential profit. Includes a leverage slider, long/short toggle, and warnings when margin exceeds portfolio. Runs locally in any browser with no internet connection required. Built with Claude in a single session.
