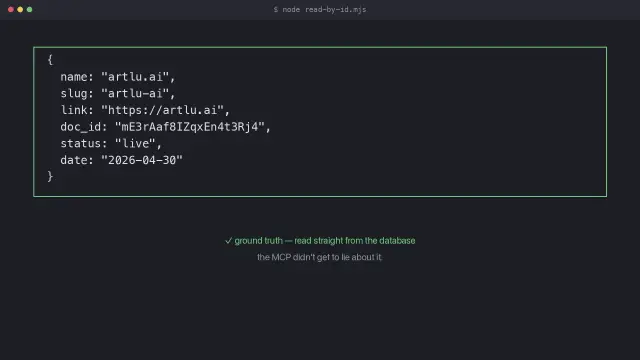
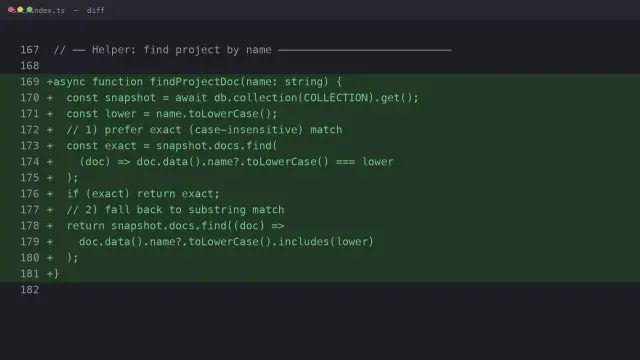
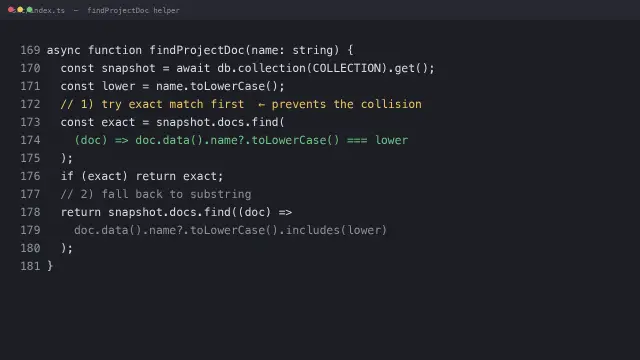
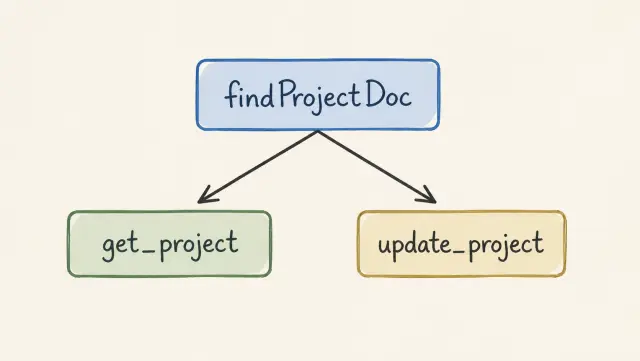
#1 · C1
Act 1 — cold open
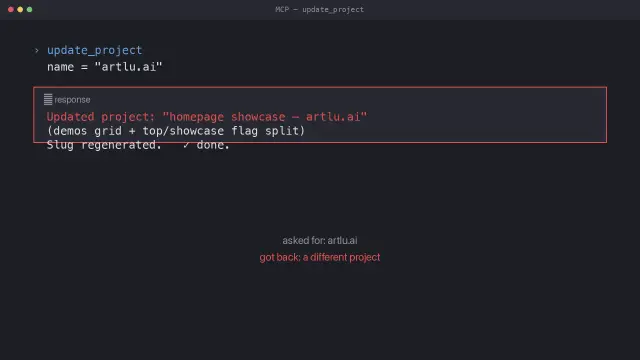
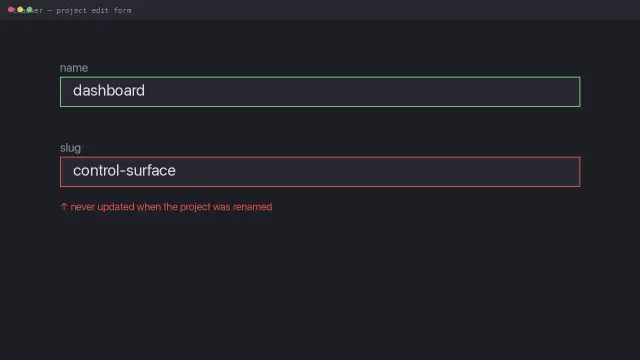
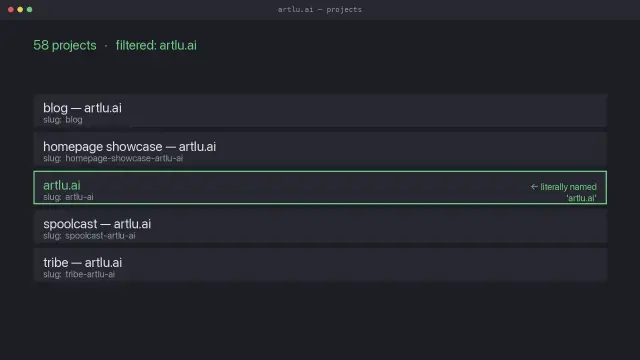
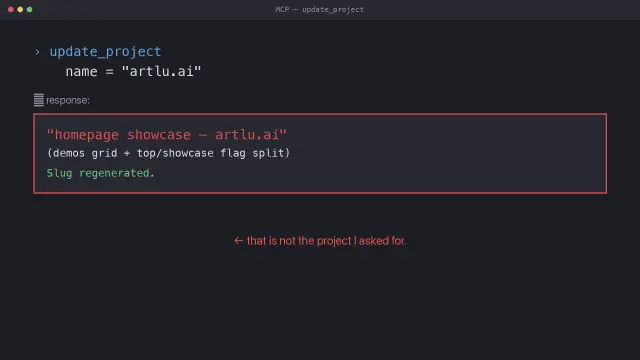
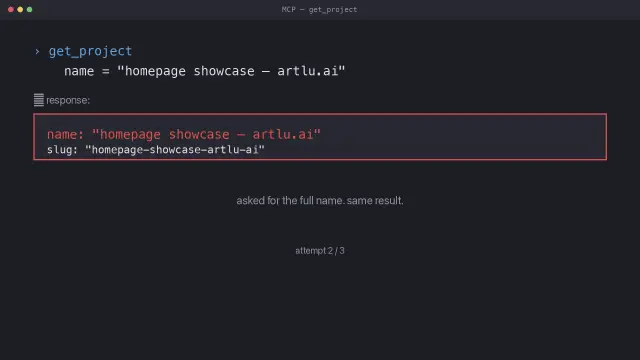
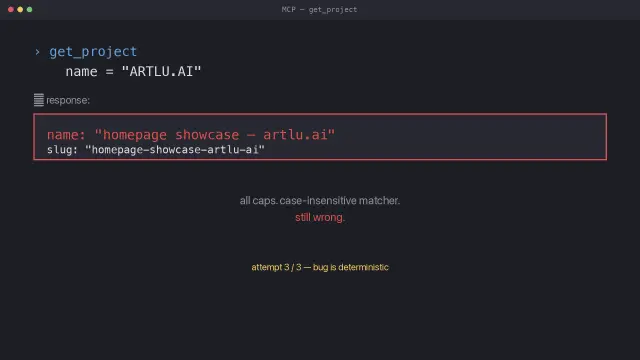
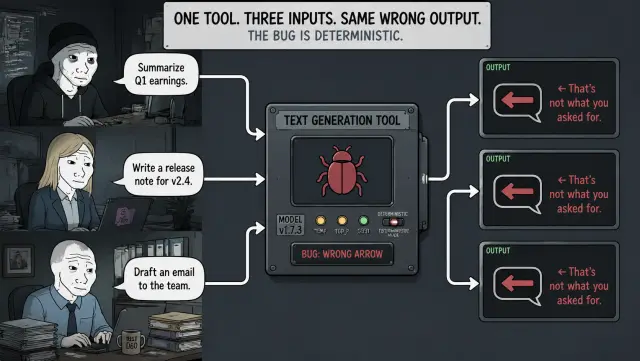
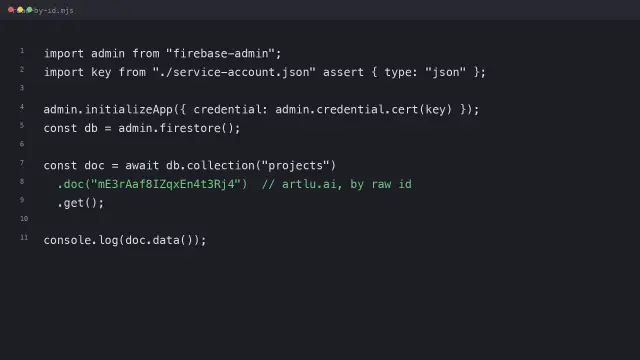
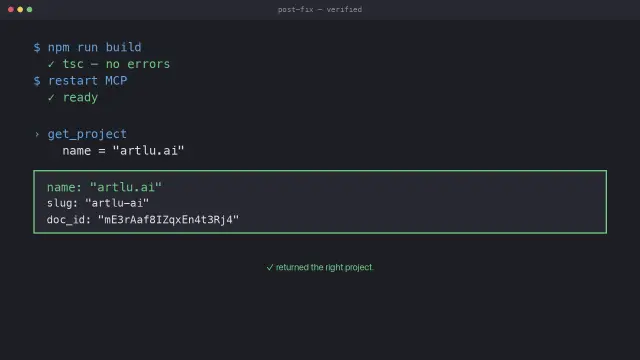
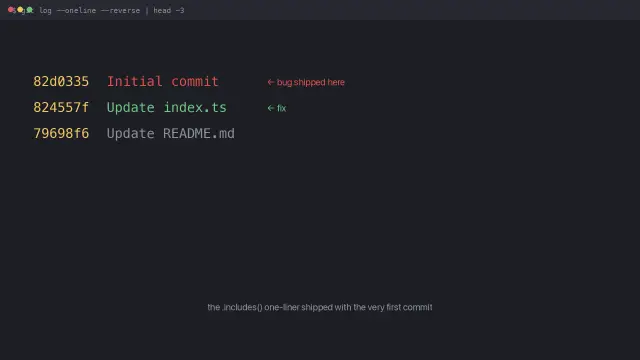
I built a tool to update my own projects.
! narration ✓ render gpt-image-2-image-to-image
Flat-shaded cartoon illustration in the modern wojak-comic style. Characters drawn with exaggerated archetypal features — weary/defeated faces (hollow eyes, gray tones, slouched posture) vs. confident/heroic faces (jawline, cheekbones, steady gaze) depending on the scene. Subtle soft cel-shading, not bold inked outlines. Muted color palette with deliberate contrast between desolate and triumphant scenes. Detailed background environments — offices, dungeons, desks, monitors, paperwork, props render with texture. Dialog bubbles rendered in-frame when characters speak. Reminiscent of Nick Col / virgin-vs-chad meme-comics but painted with care. Composition is comic-strip: one clear subject, readable at small sizes. Scene: This scene is being regenerated for a 9:16 portrait mobile video. Render the SAME single-scene composition the visual direction below describes, just framed for a tall vertical canvas instead of widescreen. Do NOT produce a multi-panel comic strip, a sequence of frames, or a before/after time-lapse — render ONE single scene matching the beat. Only if the beat description explicitly names a horizontal side-by-side layout (e.g. 'left panel ... / right panel ...', 'A vs B' compared side-by-side), restack those two panels vertically (top/bottom). For every other beat — single-character scenes, single-prop scenes, diagrams with one focal subject — keep it as ONE scene, recomposed vertically with the subject filling the portrait frame. Keep all declared on_screen_text legible inside the portrait canvas. Existing style anchor applies unchanged. Render exactly this text on the frame, hand-lettered in the session style: "MCP".